
Claude Opus 4.1 is Anthropic’s most powerful large language model to date, built on the fourth-generation Claude architecture.
It is a hybrid reasoning model, meaning the same model can function in a standard mode for quick responses or enter an extended thinking mode for deeper, step-by-step reasoning.
This hybrid design lets developers choose between faster answers and more exhaustive problem-solving without switching to a different model.
While Anthropic hasn’t disclosed the exact parameter count or internals, Claude Opus 4.1 is known to be a transformer-based foundation model trained on a massive corpus and fine-tuned with alignment techniques (e.g. Constitutional AI and human feedback) to follow instructions precisely.
It features a 200K token context window, giving it an unprecedented “working memory” for very long prompts and conversations. In practice, this means Claude Opus 4.1 can ingest large codebases or lengthy documents and still reason about them coherently.
Developers can also enable extended thinking mode to allow the model to spend more computation on hard queries – essentially letting Claude “think longer” and even use tools during its reasoning process.
In summary, Claude Opus 4.1’s architecture combines a high-capacity transformer model with novel reasoning capabilities (normal vs. extended modes) and an extremely large context window, making it a flexible AI assistant for complex tasks.
Token Limits and Context Handling
One of the standout features of Claude Opus 4.1 is its massive context window. The model supports up to 200,000 tokens of input context and can generate up to 32,000 tokens in its output.
In practical terms, 200k tokens is roughly equivalent to ~150,000 words of text (hundreds of pages), allowing developers to provide extensive background material, multi-file code inputs, or long dialogue history without running out of context.
All prior user messages and Claude’s responses accumulate in this window, so Claude can maintain continuity over very lengthy sessions. The context handling is designed linearly – earlier messages remain fully in scope until the limit is reached.
Notably, when using the extended thinking mode, the intermediate “thought” tokens are counted against the context limit but are automatically removed from the visible conversation history to avoid polluting subsequent prompts.
This means the model can reason internally at length (up to a developer-defined thinking budget) without forgetting earlier user instructions.
The input/output specifications for Claude Opus 4.1 follow a chat paradigm: you send a series of messages (as JSON) with roles like user (your prompts) and assistant (Claude’s replies), and the model returns a text completion as its answer.
Each API call can include a max_tokens parameter to control the length of Claude’s generated output (up to the 32k limit).
In summary, developers should take advantage of the huge context window to include all relevant information or documents in a single query, and utilize the token limits to balance response length.
Keep in mind that very large contexts will increase latency and cost, so use the context thoughtfully (e.g. by summarizing or chunking extremely large inputs if possible).
Supported Modalities (Text, Code, and More)
Claude Opus 4.1 is primarily a text-based model, but it supports multiple input modalities beyond plain natural language text. According to Anthropic and partner documentation, Claude Opus 4.1 accepts text, code, and images as inputs, and produces text as output.
In practice, “code” is just treated as text (the model is particularly adept at understanding and generating programming code, as detailed later). The more novel capability is vision support: you can provide image files (e.g. PNG, JPEG, GIF, WebP) to Claude and ask questions about them.
For example, a developer can upload a diagram or a chart image and prompt Claude to interpret it. Claude will analyze the visual content and respond with a textual description or answer.
Anthropic’s documentation notes you may include multiple images in one request (up to 100 images via API) and the images will be factored into Claude’s reasoning.
There are some limits on image size and quantity (images larger than ~8K×8K pixels or more than 32MB total may be rejected) and they count toward the token quota by an approximate encoding scheme.
In addition to raw images, Claude Opus 4.1 has PDF support: you can provide PDF documents for Claude to process, and it will extract and comprehend both the text and any visual elements like charts or tables within the PDF.
This is extremely useful for tasks like analyzing reports, research papers, or forms – you can literally feed a PDF and ask Claude questions about its contents.
Keep in mind that outputs are textual only; Claude does not generate images or other media (it cannot create new graphics or edit images, only interpret what you give it).
Also, audio input is not supported – all inputs must be text or image-based. In summary, Claude Opus 4.1 is a multimodal model supporting text and code understanding as well as image/PDF analysis, making it versatile for use cases from reading diagrams to writing code. Its outputs will always be text (which can, of course, include things like code snippets, markdown, JSON, etc., as directed).
Key Capabilities and Strengths
Claude Opus 4.1 exhibits state-of-the-art performance across a range of reasoning and generation tasks. Some of its most notable capabilities for developers include:
Advanced Coding Assistance:
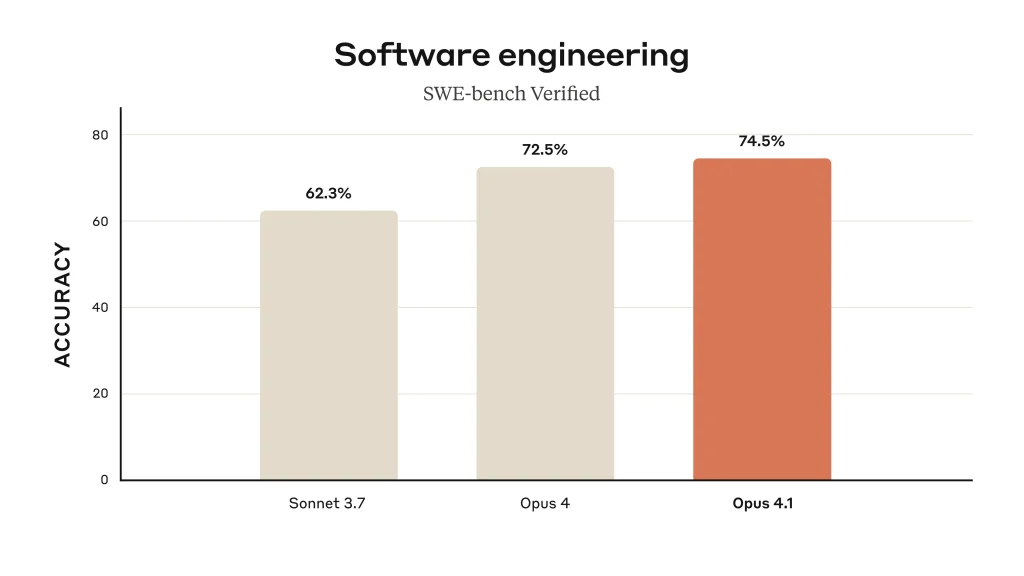
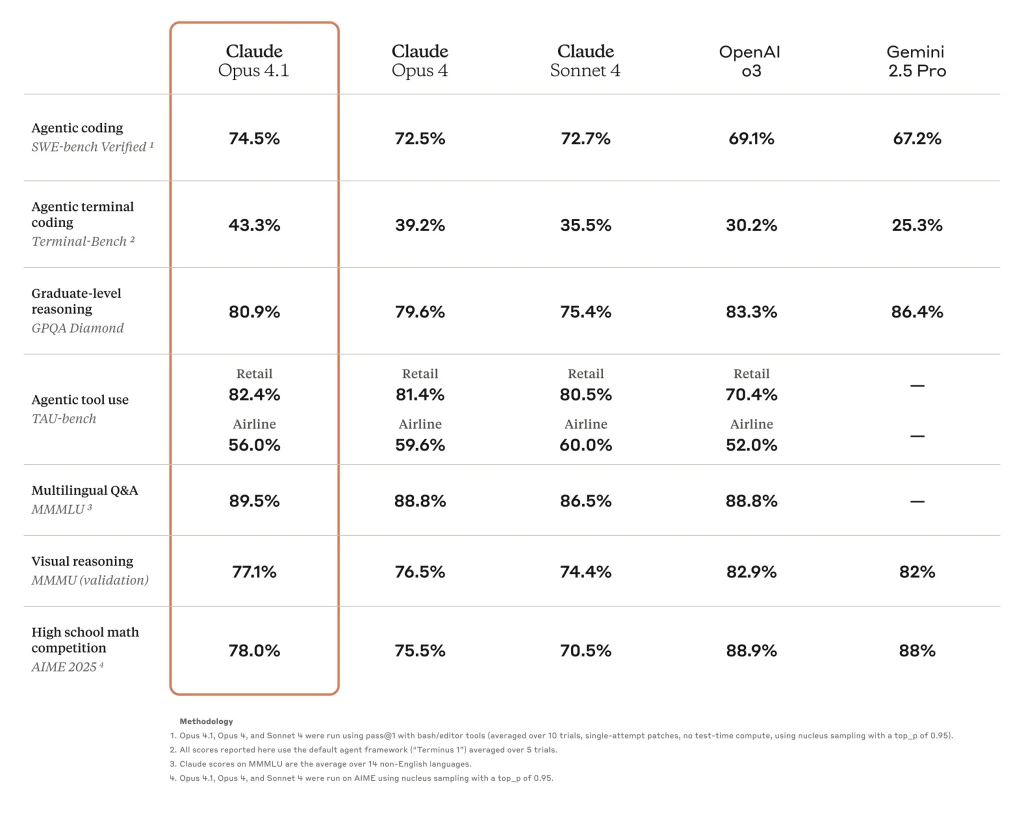
Claude Opus 4.1 is currently one of the top AI models for coding. It significantly improved coding benchmarks, achieving 74.5% on the SWE-bench (Software Engineering benchmark) Verified test – this is a leap over its predecessor and on par with or better than other leading code models. In practical terms, Claude can understand complex codebases, generate new code, refactor existing code across multiple files, and help debug issues with high precision. GitHub’s team noted that Opus 4.1 showed notable gains in multi-file code refactoring tasks, and Rakuten’s engineers reported it can pinpoint the exact corrections needed in a large codebase without introducing bugs or unwanted changes. This means developers can trust Claude to handle delicate modifications in code (e.g. fixing a bug in a project) while respecting the parts of the code it shouldn’t touch. With up to 32K tokens of output, Claude can even output very large code files or extensive diffs in one go. It also has an improved “code taste,” meaning the style and structure of its generated code align better with human-like best practices. Use Claude Opus 4.1 for tasks like writing functions or classes given a description, generating unit tests, converting pseudocode to code, and providing step-by-step explanations of code logic. It’s effectively a AI pair programmer that can operate at the scale of real-world, multi-file projects.
Deep Reasoning and Problem Solving:
Thanks to the extended thinking feature, Claude can tackle long-horizon reasoning problems that require many intermediate steps or careful planning. Anthropic notes that Claude Opus 4.1 delivers “sustained performance on long-running tasks that require focused effort and thousands of steps”, significantly expanding what AI agents can solve. For example, it can engage in complex mathematical reasoning, solve tricky word problems, plan out multi-step workflows, or even simulate an “AI agent” working through a decision tree. When extended thinking mode is toggled on, Claude will essentially “think out loud,” producing a chain-of-thought and using tools if available (more on tool use below), until it arrives at a solution. This yields far better results on complex tasks like multi-hop question answering, logical puzzles, strategic planning, or troubleshooting. Notably, Claude’s chain-of-thought is visible in this mode (you can capture or review the reasoning steps), which can help in understanding why it gave a certain answer. It’s best used for use cases where accuracy is more important than speed, since this mode incurs additional latency. In normal mode (extended thinking off), Claude is still a very strong reasoner – it was trained on a wide variety of Q&A and knowledge tasks – but the extended mode truly unlocks a new level of performance for the hardest problems.
Tool Use and Function Calling:
Claude Opus 4.1 can be augmented with external tools or functions to extend its capabilities beyond what’s in its model weights. Anthropic’s API allows developers to define custom tools (functions) that Claude can invoke, or to enable built-in tools. For example, you can provide Claude with a get_weather(location) function, a database query tool, or a web search function. Claude will then decide during its response if it should call one of those tools (the API returns a structured call which your code can execute) and then incorporate the results back into its answer. This is analogous to “function calling” in other AI APIs. According to Anthropic, “Claude is capable of interacting with tools and functions, allowing you to extend Claude’s capabilities to perform a wider variety of tasks.” In practice, this means developers can hook Claude into real-world actions or data sources: e.g. calling an API to get live data, executing some code, looking up information online, etc., and then have Claude continue the conversation with that new information. Claude Opus 4.1 supports tools like a web search (Anthropic provides a built-in web search tool in their platform), a bash shell, a text editor, a code execution sandbox, and more (these are available through Anthropic’s Claude Code interface or API). The model was specifically trained to use these tools effectively when available – Anthropic calls this agentic capability. For instance, Claude can autonomously decide to use a web_search tool to fetch information and then answer a user’s question with sources. It can iterate with tools in a loop, enabling it to function as an AI agent solving multi-step tasks (think of a scenario like browsing a website, extracting data, then writing a summary). This hybrid of natural language reasoning with tool usage is a major strength of Claude Opus 4.1 for developer applications.
Knowledge and In-Depth Analysis:
Claude has been trained on an extensive dataset (including books, websites, code, etc. up to a recent cutoff), which gives it a broad base of world knowledge. It demonstrates strong performance on academic and general knowledge benchmarks (for example, high scores on MMLU, a test of multitask knowledge across domains). Developers can leverage Claude 4.1 for tasks like research assistance, data analysis, and summarization. Because of the large context, you can feed in whole documents or even multiple documents (or database dumps, transcripts, etc.) and ask Claude to analyze them. Anthropic reports that Opus 4.1 “can conduct hours of independent research—simultaneously analyzing everything from patent databases to academic papers and market reports, delivering strategic insights”. In other words, it’s great at synthesizing information from large collections of text. It also handles “agentic search” well, meaning if you give it access to search results or a knowledge base, it can sift through and combine information to answer complex questions with citations. Additionally, Claude’s language generation abilities are excellent: it produces coherent, well-structured explanations and summaries, making it suitable for report generation or explanatory chatbots.
Natural Language Generation and Conversation:
As a conversational AI, Claude Opus 4.1 excels at producing human-like, contextually appropriate responses. It has a “rich, deep character” and can generate high-quality creative writing and content. This is useful for developers building content creation tools, storytelling applications, or simply user-facing assistants. Claude can adapt its style/tone based on instructions – for instance, writing in a formal business tone, or adopting a friendly persona – and maintain that consistency over a long dialogue. It has been noted to follow instructions with high precision, especially compared to earlier models. This means if you specify a format or list of requirements for the output, Claude will generally comply. It’s also capable of multilingual understanding and generation (the model can respond in many languages, though English is its strongest; extended reasoning is recommended to be done in English for best results, with translation to other languages in the final output if needed). Overall, Claude Opus 4.1’s capability set spans from hard reasoning and coding tasks to open-ended creative generation, making it a general-purpose powerhouse for developers.
Known Limitations and Caveats
Despite its advanced capabilities, Claude Opus 4.1 has some important limitations and caveats developers should keep in mind:
Hallucination and Accuracy:
Like all large language models, Claude can sometimes produce incorrect or fabricated information (a phenomenon known as hallucination). While it is generally factual on common knowledge and it improved detail tracking, it is not infallible. Low-quality or ambiguous inputs can increase the chance of mistakes. For example, with images, Anthropic notes Claude “may hallucinate or make mistakes when interpreting low-quality, rotated, or very small images”. By extension, if given unclear questions or insufficient context in text, Claude might fill in gaps with incorrect guesses. Developers should always review and verify Claude’s outputs, especially for high-stakes tasks. It’s wise to implement a human-in-the-loop or validation step if you’re using Claude for things like medical, legal, or financial advice.
Limited Visual Precision:
While Claude can analyze images, it has some specific vision limitations. It struggles with precise spatial reasoning – e.g., tasks like reading an analog clock from an image or pinpointing exact coordinates in an image are challenging for it. It can count objects approximately but might not be exact if there are many items. Claude also cannot identify people in images or confirm someone’s identity (it is explicitly prevented from doing face recognition or naming people in images). It also will not determine if an image is AI-generated or not. These are by design due to policy or technical limits. If your application needs fine-grained image analysis (like detailed facial recognition, medical image diagnosis, or reading tiny text in images), Claude’s vision may not be sufficient. Anthropic also enforces that Claude will refuse disallowed image content – e.g., it won’t analyze explicit or extremely graphic images, in line with their Acceptable Use Policy. In summary, use the vision feature for broad understanding of images and documents, but not for tasks requiring pixel-perfect accuracy or policy-violating content.
Output Control and Format Constraints:
While Claude is excellent at following instructions, there can be cases where ensuring a very strict output format is tricky. If the response needs to be in a particular JSON schema or a very rigid format, minor deviations might occur unless you use tools/function calling. The introduction of function calling (tools) mitigates this by letting you get structured data as model “function outputs.” But if you’re not using that feature, you should anticipate possibly doing some post-processing or validation on Claude’s output format. Additionally, extremely long outputs (tens of thousands of tokens) may sometimes be cut off if they exceed max_tokens or if the context window is heavily utilized. The 32k output limit is large, but if your prompt is also near the 200k limit, the model might not always fully utilize the max output. Always set max_tokens a bit above what you expect and handle cases where the completion stops mid-sentence (you can often prompt Claude to continue if needed).
Latency vs. Accuracy Trade-off:
Enabling extended thinking mode incurs a performance cost. When Claude is in this deep reasoning mode, it may consume hundreds or thousands of “thinking” tokens internally, and each of those steps takes time. Thus, responses can be significantly slower when extended thinking is on (potentially several seconds or more for complex problems, depending on the thinking budget). Developers should only use extended thinking for queries that truly need it, and keep it off for straightforward tasks where a quick answer is sufficient. Anthropic suggests starting with a minimal thinking budget (the minimum is 1024 tokens of thinking) and increasing only as needed to find the optimal point. The model often yields diminishing returns beyond a certain amount of “thinking”. In fact, for some tasks, a normal response may be completely fine and faster. It’s important to tune the thinking settings based on your use case – you might expose a toggle to users or dynamically enable it for only particularly complex inputs. Also note that if you try to force an extremely large thinking budget (e.g. 50k or 100k tokens of reasoning), you might hit API timeouts or rate limits. Very long running requests can fail, so for extremely complex jobs it may be better to break the problem into sub-tasks or use batch processing. In summary: extended thinking is powerful but use it judiciously, and design your system to handle the increased latency.
Knowledge Cutoff and Updates:
Claude’s training data extends to a recent timeframe (as of Opus 4.1’s release in Aug 2025, it likely includes data up to 2024 or early 2025, though exact cutoff isn’t publicly stated). It may not be aware of very recent events or specialized new information that wasn’t in its training. If asked about something brand-new or extremely niche, it might respond that it doesn’t know or it might guess incorrectly. This is where the web search tool or providing reference text becomes important. As a developer, if up-to-date knowledge is required, consider either giving Claude the latest info via the prompt (you can feed documents or results into the 200k context), or enable a tool like web search so it can retrieve current data. Otherwise, Claude might have blind spots on cutting-edge developments post-training.
Content Safeguards:
Anthropic has implemented strong safety filters and a Constitutional AI alignment approach in Claude. This means the model will refuse or safe-complete requests that violate its content guidelines (e.g. requests for disallowed content such as explicit violence, hate, self-harm instructions, etc.). Developers should be aware that if your application tries to prompt Claude for something against policy, you’ll get a refusal or a sanitized answer. These safeguards are generally a feature (to prevent misuse), but it can be a limitation if you expected the model to handle edgy content. The system card for Claude 4.1 details the safety improvements, but as a rule of thumb: Claude will decline to produce illicit or highly sensitive content. It also tries to avoid giving harmful advice or confidential information. If your use case involves moderated content, ensure you understand Anthropic’s usage policies and perhaps provide user guidance on what is not allowed.
In summary, Claude Opus 4.1 is extremely capable, but not perfect. Plan for occasional errors, especially on ambiguous queries. Use human review for critical outputs. Leverage the model’s strengths (reasoning, coding, etc.) while compensating for its weaknesses (factuality, strictness of format) through prompt design, tool use, and oversight.
Integration into Developer Workflows (API Access, SDKs, etc.)
Integrating Claude Opus 4.1 into your application is straightforward thanks to Anthropic’s developer platform and APIs. Here’s how to get started and what to consider:
Accessing the Claude Opus 4.1 API: You’ll first need an Anthropic developer account (sign up on the Claude Console) and an API key. Once you have your API credentials, you can call Claude via RESTful API endpoints. Claude Opus 4.1 is accessed by specifying its model ID in your API requests.
For the August 5, 2025 release, the model is identified as "claude-opus-4-1-20250805" in the API. Anthropic may update model IDs with new versions or dates, so check their docs for the latest exact string. An example API call using curl would look like:
curl https://api.anthropic.com/v1/messages \
-H "Content-Type: application/json" \
-H "x-api-key: $API_KEY" \
-H "anthropic-version: 2023-06-01" \
-d '{
"model": "claude-opus-4-1-20250805",
"messages": [ { "role": "user", "content": "Hello, Claude!" } ],
"max_tokens": 1000
}'In this JSON, you provide the conversation in the messages array (roles can be "user" for your prompts, "assistant" for Claude’s responses, and optionally a "system" role or an initial assistant message for instructions). The API will return Claude’s reply in a JSON payload. Anthropic’s API supports streaming output as well, if you prefer token-by-token streaming responses.
SDKs and Developer Tools: Anthropic offers official SDKs to simplify integration. There is a Python SDK and a TypeScript/Node SDK for Claude, which wrap the HTTP calls and handle auth, streaming, etc. for you.
Additionally, Anthropic provides a Claude Console (web IDE) where you can prototype prompts and even save them. For coding tasks, Claude Code is a specialized interface (and API mode) that allows long-running coding sessions with background task execution.
Claude Opus 4.1 is available in Claude Code, meaning you can delegate intensive coding jobs to it asynchronously (useful for CI/CD or batch code analysis scenarios).
The model is also accessible through third-party cloud platforms: it’s integrated into Amazon Bedrock and Google Cloud Vertex AI as a managed service.
If you’re on AWS or GCP, you can leverage those services to use Claude via their SDKs and get features like scaling, monitoring, or integration with other cloud tools.
Keep in mind that when using these platforms, the model might be named slightly differently (for example, on Vertex AI it’s listed as claude-opus-4-1@20250805) but it’s the same Claude Opus 4.1 under the hood.
Authentication and Security: All API calls require your API key to be included (x-api-key header). Treat this key like a password – keep it out of client-side code or publicly exposed configs. Anthropic uses TLS for API endpoints, and requests should be made server-to-server if possible.
The API supports specifying an organization or workspace ID if you have multiple projects, but for most cases your key is enough to authenticate. There are also features like rate limit headers and auditing logs in the console to monitor usage.
If you work with sensitive data, note that Anthropic’s terms state they don’t use your API data to train models by default (opt-out) and they have a data privacy policy. Still, you might consider anonymizing personal data before sending it to the API or using on-premise options if available in the future.
Rate Limits and Quotas: Anthropic imposes rate limits to ensure fair use and system stability. By default, new organizations start in Tier 1, which allows around 50 requests per minute and 30,000 input tokens per minute for Claude Opus 4.x models.
This is roughly equivalent to sending maybe one or two very large queries per minute (since 30k tokens is a lot of text) or many small queries.
The limits scale with usage tiers – as you spend more and move to Tier 2, 3, 4, those limits increase (e.g. Tier 2 might double the allowance, etc.).
By Tier 4, and especially with a custom enterprise plan, you can get much higher throughput or even unlimited concurrency by arrangement. The console will automatically upgrade your tier once you hit certain monthly spend thresholds.
It’s important to handle HTTP 429 rate-limit responses in your code – if you exceed the per-minute limits, the API will return an error with a Retry-After header telling you when to retry.
Using prompt caching can effectively raise your throughput: Anthropic’s system only counts uncached tokens toward some limits, so reusing prompts via caching can give you much higher effective token throughput.
Also note there are separate limits if you use the 1M token context (currently a beta feature for certain users) – those heavy requests have their own token/minute cap.
For most developers, the standard 200k context is plenty. Just be mindful of the rate limits when scaling your app; you might need to batch requests or queue them if hitting limits frequently.
Pricing: Using Claude Opus 4.1 is a paid service. As of its release, pricing is set at $15 per million input tokens and $75 per million output tokens (i.e., $0.015 per 1K input tokens and $0.075 per 1K output). This is the same pricing as the previous Claude 4 model.
To put it in perspective, 1,000 tokens is roughly 750 words. So a prompt of 2,000 words and an answer of 500 words would cost a few fractions of a cent in input and a few cents in output. Given the large context, costs can add up if you routinely send extremely long prompts or get very long responses.
Anthropic provides cost-saving features: for example, prompt caching can cut costs up to 90% for repeated queries (cached tokens are billed at 10% of normal cost), and batch requests (sending multiple prompts in one API call) can save around 50% on overhead.
Always refer to Anthropic’s official pricing page for updates, as prices may change or volume discounts might apply for enterprise deals.
Also, note that if you’re using Claude via a platform like AWS Bedrock or Vertex AI, the pricing may be through those services (e.g., Google might charge per 1000 tokens in their own units).
In summary, integration involves getting API access, respecting rate limits, and possibly using the provided SDKs or cloud integrations for convenience.
With the Claude Opus 4.1 API in hand, you can embed this model into your workflows – from back-end services that call it for analysis, to interactive chatbots, to IDE plugins for coding assistance.
Just be sure to monitor your usage (tokens and requests) to stay within quotas, and optimize costs by using caching and batching where appropriate.
Best Practices for Prompting and System Design with Claude 4.1
To get the most out of Claude Opus 4.1, developers should follow best practices in prompt engineering and system setup. Here are some key guidelines:
- Be Clear and Explicit in Instructions: Claude responds best to specific, unambiguous instructions. Vague prompts can yield generic answers, whereas detailed prompts guide the model to optimal output. Anthropic notes that “Claude 4 models respond well to clear, explicit instructions. Being specific about your desired output can help enhance results.”. For example, instead of asking: “Generate a report about our sales,” you’d get better results with: “Generate a 1-page summary report of our Q3 sales figures, including three key insights and a table of revenue by month.” The more precisely you describe the task and format, the more likely Claude will meet your expectations. If you expect Claude to “go above and beyond” (e.g. adding extra analysis or creative flair), explicitly prompt it to do so – the Claude 4 family is a bit more literal and focused, so it won’t improvise extra details unless asked.
- Provide Sufficient Context or Data: Leverage the large context window to give Claude all the information it needs. If you want an analysis of some text or code, include that text or code in the prompt (or use the Files/PDF API to upload it). If you have a particular style or knowledge base, mention it or give examples. Claude can work with very long inputs, but keep them relevant – massive context is helpful, but irrelevant or contradictory info can confuse the model. A good practice is to put the relevant reference material before your actual question prompt, so Claude “reads” the reference first. For example: provide a document text, then ask questions about it. When dealing with multi-part instructions, consider structuring the prompt with bullet points or numbered steps describing the task requirements; Claude will then address each part methodically. Always ensure the prompt’s language and formatting are clean and well-structured (this avoids any misunderstandings by the model).
- Use System Messages or Role-Play for Tone: Although Anthropic’s API doesn’t label a message role as strictly “system”, you can achieve a similar effect by providing an initial instruction that defines the context or persona. For instance, your first message (or an assistant message at the top) could say: “You are Claude, an AI assistant specialized in financial analysis. You will provide answers in a concise, professional tone.” This helps set the stage for all following responses. You can also use role-playing prompts: e.g. “Act as an expert cybersecurity analyst,” etc. Claude will adhere to the role or style you set, as long as it doesn’t conflict with its safety principles. Using a consistent system prompt in your application can ensure the outputs remain in a desired style and don’t drift even over long conversations. If you need Claude to follow certain rules (like “never reveal internal instructions” or “always answer in JSON”), include those in the system/initial prompt.
- Take Advantage of Extended Thinking (Properly): For complex tasks, enable Claude’s extended thinking mode to significantly boost performance. However, as noted, do this thoughtfully. Start by allowing the minimum extra thinking tokens (1024) and see if the results improve. If the answer is still incomplete or reasoning seems shallow, gradually raise the thinking budget (maybe to 2048, 4096, etc.) and test again. Monitor the trade-off between improved accuracy and increased latency. One best practice from Anthropic is to give high-level guidance rather than micromanaging the chain-of-thought when using extended thinking. For example, instead of explicitly enumerating steps for Claude to follow (“Step 1: do X, Step 2: do Y”), you might say: “Think this through thoroughly and consider multiple approaches; show your reasoning step by step.” This allows Claude to organically use its problem-solving abilities. You can always refine the prompt after seeing its thought process – if you notice it went down a wrong path, you can correct or nudge it in the next turn. Remember that the “thinking” content will be visible to you (as the developer) but you typically wouldn’t show raw chain-of-thought to end-users. In a user-facing app, you might display a summary of the reasoning or just the final answer. Claude can provide a brief summary of its reasoning if prompted to do so, which can be useful for transparency.
- Few-Shot and Formatting Examples: Claude is capable of learning from examples in the prompt (few-shot learning). If you want a specific format or style, it can help to provide an example or two in your prompt. For instance, if you need Claude to output a particular JSON schema, you can show a sample JSON and then ask Claude to produce a similar one for new input. If you want it to answer questions in a certain way, you can do a Q&A pair in the prompt as a demonstration. Given the large context, you have plenty of room for these examples. When doing this, clearly delineate the example context, perhaps with separators or by saying “Example 1:” etc., so Claude doesn’t get confused about what’s example vs. what it needs to do. For extended thinking scenarios, Anthropic suggests you can even include examples of the thought process by using
<thinking>tags around the example chain-of-thought. Claude will then mimic that style in its own reasoning. However, often it’s enough to just supply final output examples, as Claude 4.1 is already quite good at following patterns. - Control Output Length and Detail: If you require a concise answer or, conversely, a very detailed one, you should specify that. Claude by default tends to be helpful and may give a fairly thorough answer, but you can instruct it like “Answer in 3 sentences” or “Provide a one-paragraph summary” or “List 5 bullet points.” It will generally adhere to those constraints. For long reports, you can ask it to structure the output with headings, lists, tables, etc. – Claude is quite capable of producing well-formatted Markdown or HTML if asked. One thing to watch for: if you ask for extremely long outputs (tens of thousands of tokens), make sure to increase the
max_tokensparameter accordingly and be prepared for longer generation times. You might need to break very long outputs into sections (for example, generate a report section by section) if you hit any performance issues. - Utilize Tools/Function Calling for Complex Actions: When building systems that require Claude to perform actions (like look up info, do calculations, interact with external systems), use the function calling (tool use) feature rather than expecting Claude to do it all internally. Define a function for the action and let Claude invoke it. For instance, instead of hoping Claude “knows” the weather, give it a
get_weathertool. Claude will output a JSON like{"action": "get_weather", "params": {"location": "San Francisco, CA"}}if properly prompted, which your code can detect and fulfill, then feed the result back for Claude to continue. This approach not only gives more accurate results (live data vs. model’s memory), but also keeps the model’s responses grounded. When implementing this, follow Anthropic’s tool use guidelines: provide a clearname,description, and input schema for each tool in the API call. Ensure your handling code is robust – e.g., if Claude calls a function incorrectly or the function fails, have a strategy (maybe return an error message for Claude to see, or a default response). In practice, Claude is quite good at tool use if the prompt says it has tools available. For example, you might prompt: “You have access to a web search tool. If the user’s question requires up-to-date information, first use the tool and then answer.” The combination of tools + Claude’s reasoning can yield very powerful agents. Just remember to monitor for any misuse (Claude should not call tools for disallowed purposes – Anthropic’s system usually prevents that, but keep an eye out). - Maintain Conversation State and Boundaries: If you’re using Claude in a multi-turn conversation (like a chat with a user), manage the turn-by-turn context carefully. The 200k token context will include everything by default, but it’s good practice to occasionally prune or summarize very old turns if the conversation goes extremely long (for efficiency). Anthropic’s documentation mentions a rolling window approach can be used for chat interfaces, or you might summarize earlier parts of the conversation and insert that summary in place of raw logs. Also, be cautious about user-provided content that goes into the prompt – since the model will treat it as authoritative context, malicious or corrupt input could cause issues. Implement content filtering on user inputs if your app allows arbitrary prompts to pass through (to avoid feeding extremely harmful content into Claude that could produce unpredictable results, even if it tries to refuse).
- Testing and Iteration: Finally, treat prompt design and usage of Claude Opus 4.1 as an iterative process. Try out your prompts in the Claude Console or a dev environment, see how Claude responds, and refine your approach. Use Anthropic’s evaluation tools or your own metrics to measure success (they even have an Evaluation Tool to test prompts systematically). If you notice patterns of error (say, certain types of questions lead to hallucination), adjust your prompt to mitigate that (e.g., add a disclaimer like “If you don’t know the answer, say you are unsure” or provide additional context). For reducing hallucinations, Anthropic suggests techniques like giving Claude an opportunity to double-check its answer. You can prompt it with something like: “Explain how you arrived at that answer and verify if each step is correct.” This can induce the model to catch its own mistakes. Another trick is using the
<!--\n \n-->HTML comment tags in a system prompt to inject hidden instructions (Anthropic models respect that syntax to hide text from the user, similar to Markdown comments), but use this carefully as it’s more of a low-level technique.
By following these best practices – clear instructions, rich context, using extended thinking and tools appropriately, and iterative prompt tuning – you can harness the full potential of Claude Opus 4.1 in your applications. This model is quite developer-friendly, and with the right prompting strategy, it can perform astonishingly well on tasks that were previously very challenging for AI.
Ideal Use Cases for Claude Opus 4.1
Claude Opus 4.1 is a general-purpose large model, but its unique strengths make it especially suited for certain scenarios. Anthropic themselves recommend using Opus 4.1 for your most demanding, intelligence-intensive use cases. Here are some ideal use cases for developers to consider:
- Autonomous Agents and Complex Task Automation: If you are building an AI agent that needs to carry out multi-step tasks or operate tools, Claude Opus 4.1 is an excellent choice. Its ability to maintain long-term coherence and perform extended reasoning means it can handle long-horizon autonomous work where others might fail. For example, you might create a customer service agent that can troubleshoot technical issues by asking multiple questions and even running diagnostic commands via tools – Claude can manage this multi-turn interaction reliably. Another example is an AI project manager that plans and updates tasks over a week-long project, or an agent that autonomously researches a topic by querying databases and assembling a report. Claude’s strong agentic reasoning (as evidenced by high TAU benchmark scores for agent tasks) and tool use make it perfect for complex agents that need frontier intelligence and reliability.
- Enterprise Knowledge Assistants and Data Analysis: Claude 4.1 shines in making sense of large volumes of text and data. A great use case is an enterprise knowledge assistant: feed it your company’s knowledge base, wikis, PDFs, or even connect it to a vector database of documents, and use Claude to answer employees’ questions or generate briefs. It can extract insights from financial reports, legal contracts, scientific papers, and so on. Thomson Reuters, for instance, used Claude to analyze a massive litigation document set and populate a summary judgment with precise citations – a task involving understanding nuanced legal text and linking facts to claims. Claude is ideal for such deep research tasks. Similarly, for data analysis: Claude can take in CSV data or the text of spreadsheets and help interpret it. It’s been praised for things like analyzing complex Excel files and financial models, since it can describe and reason about the data in them. If you need an AI to digest and explain data (numerical or text data), Claude’s extensive context and reasoning make it a top contender. Just ensure to verify critical outputs as always.
- Large-Scale Coding Projects and Codebase Management: For developers, one of the killer use cases of Claude Opus 4.1 is as an AI coding assistant, especially for large or legacy codebases. You can plug Claude into your development workflow to help with tasks such as: code review (it can read an entire repository and suggest improvements), automated refactoring (e.g., “upgrade this library usage across the codebase”), writing new modules based on extensive context (e.g., it can understand your project’s coding style and architecture from the repo and write code that fits in), and debugging assistance (paste a stack trace and relevant code files, and Claude can analyze the problem across files). Its performance on coding benchmarks and multi-file editing tasks is industry-leading. It’s also useful for code documentation: you can ask Claude to generate documentation or comments for code, since it can take in the whole code and produce summaries. Many developers use Claude in their IDE or via a CLI for these purposes. If you have long-running coding tasks, Claude Code (with Opus 4.1) can even execute or test code in the background. In short, Claude for developers means you have a capable AI pair programmer that can operate at scale, handling thousands of lines of code in context.
- Long-Form Content Generation (Writing & Creative Tasks): Another great use case is any application that requires generating or transforming large texts. For example, writing articles, reports, or even books with the help of AI. Claude’s 200k context lets it incorporate an outline or reference materials for factual consistency. Its output quality in terms of prose is very high – often described as having a good balance of “intelligence and taste” in its writing. You could use Claude to draft marketing content, technical whitepapers, or elaborate narratives. It’s also useful for summarization tasks: since it can read very long texts, you can feed a whole whitepaper or a huge Slack chat log and ask for an executive summary or action points. This can be integrated into productivity tools or document management systems for summarizing meeting transcripts, legal documents, etc. Claude’s creative abilities also allow for generating fiction, dialog, or brainstorming ideas, which could be utilized in creative writing apps or game design (it can carry on character dialogs, describe scenes in detail, etc., as guided by the user).
- High-Precision Question Answering and Advisory Systems: If you need an AI to provide expert-level answers in specialized domains (medicine, law, engineering, etc.), Claude 4.1 is suitable given proper conditioning. It performed strongly on knowledge benchmarks (e.g., high accuracy on academic exam questions). For instance, you might use Claude as the backend for a medical Q&A bot for doctors – you’d fine-tune the prompting to include safety (since it’s not a doctor, it should disclaim uncertainty) but leverage its vast knowledge. Or as a legal research assistant that can cite laws and prior cases (perhaps by providing it with a database of case law in the prompt). Claude’s ability to follow complex instructions means it can be instructed to give answers with references, or in a step-by-step solution format for math problems, etc. Its multi-lingual support also means such an assistant could answer in different languages for global users. These advisory use cases benefit from Claude’s reasoning (for checking consistency) and large context (for providing lots of background info if needed).
In general, Anthropic suggests using Claude Opus 4.1 whenever your use case “needs frontier intelligence, where accuracy and capability matter more than speed or cost.”
This typically means complex, large-scale, or critical tasks. If your application is more lightweight or cost-sensitive (e.g., a quick reply chatbot with simple queries), you might opt for a smaller model in their lineup for that specific scenario.
But for the hardest problems – whether it’s coding, reasoning, or understanding vast amounts of data – Claude Opus 4.1 is an excellent tool in a developer’s arsenal.
It empowers you to build applications that perform deep analysis, maintain long conversations or processes, and solve problems that earlier AI models would struggle with.