
Claude 3.7 Sonnet is Anthropic’s most advanced AI model to date, designed with software developers in mind. Announced in early 2025, it introduced a new hybrid reasoning paradigm, meaning the model can operate in two modes – providing near-instant answers or engaging in extended, step-by-step reasoning when tackling complex problems.
Anthropic’s goal with Claude 3.7 Sonnet was to create an AI assistant that mimics human cognitive flexibility, using the same “brain” for quick tasks and deep reflection instead of relying on separate models.
“The evolution of Claude reflects Anthropic’s broader vision — from assisting individuals to pioneering independent solutions, as shown below.”

This unified approach results in more seamless and transparent interactions, which is especially relevant for developers who may need both rapid answers and detailed problem-solving from their AI assistant.
In practice, Claude 3.7 Sonnet brings substantial improvements for developer-centric tasks. Anthropic specifically optimized it for coding and engineering scenarios, and early evaluations showed best-in-class coding capabilities.
For example, internal tests and partner feedback indicated Claude 3.7 could handle complex codebases, plan multi-step code changes, and even perform full-stack updates more reliably than prior models.
It consistently produced production-ready code with fewer errors and exhibited “superior design taste” in generated front-end code according to one evaluation. In short, Claude 3.7 Sonnet was released as a powerful AI coding assistant aimed at boosting developer productivity in real-world software development.
Key features introduced with Claude 3.7 Sonnet include an extended context window, dual reasoning modes, and fine-grained control via the API. These make it highly relevant for tasks like debugging, writing documentation, or even reasoning through complex algorithms.
In the following sections, we’ll dive deeper into the model’s architecture and performance, explore concrete developer use cases, and guide you through integration steps (from API calls to IDE plugins). We’ll also cover prompt engineering techniques and important deployment considerations (rate limits, safety, etc.), equipping you with a comprehensive developer’s guide to Claude 3.7 Sonnet.
Architecture and Performance Benchmarks
Claude 3.7 Sonnet is built on a cutting-edge transformer-based architecture with innovative tweaks that enable its hybrid reasoning capability. Internally, the model can toggle between shallow and deep reasoning paths depending on the task complexity.
For simple queries, it utilizes a fast, “instant response” mode that skips unnecessary computation, delivering answers in milliseconds.
For harder problems (like intricate algorithms or math proofs), the model engages a “deep thinking” mode, processing through more transformer layers or iterative steps to produce a well-reasoned answer.
This dynamic neural architecture allows Claude 3.7 Sonnet to balance speed with depth, essentially giving developers the best of both worlds: quick responses when you need them, and thorough step-by-step solutions when required.
Context Window: One of Claude 3.7’s standout technical specs is its massive context length. It supports up to 200,000 tokens of input context and can produce outputs up to 128,000 tokens long.
This is an exceptionally large context window in the LLM landscape, allowing the model to ingest entire codebases or extensive documentation in one go.
For developers, this means you could provide an entire project’s code (hundreds of thousands of tokens) and ask Claude questions or have it generate summaries without hitting context limits.
Similarly, the model can output very large responses (over 100k tokens, if needed) – for example, generating lengthy technical documentation or multiple files of code in one response.
(By default, generally available outputs may be limited to ~64K tokens, with 128K as a beta feature.) This huge context capacity enables global reasoning across a project: Claude 3.7 Sonnet can maintain awareness of wide-ranging context – e.g. earlier conversation history, large JSON data, or multiple source files – and integrate that into its answers.
Hybrid Reasoning Modes: Claude 3.7 operates in two modes – Standard and Extended Thinking – which correspond to its dual approach to reasoning. In Standard mode, it behaves like a high-performance general LLM (an improved successor of its Claude 3.5 lineage) giving fast, direct answers.
In Extended Thinking mode, the model will deliberately spend more “thinking time”: it analyzes the problem in depth, often generating an internal chain-of-thought that can be made visible to the user for transparency. Developers can toggle modes on demand.
For example, during an API call or in a platform like AWS Bedrock or the Claude console, you might enable extended mode when you want Claude to deeply reason (solving a tricky bug or complex algorithm design), and disable it when you just need a quick code snippet or answer.
Under the hood, extended mode allocates a portion of the model’s output tokens to “thinking” steps, which improves performance on tasks like math, logical reasoning, and multi-step coding challenges.
Notably, you can control exactly how many tokens Claude is allowed to spend thinking (the “reasoning budget”) via the API – for instance, limit it to 2,000 tokens of reasoning for time-sensitive tasks, or allow 10k+ tokens for very complex jobs. This adjustable reasoning budget lets you fine-tune the speed vs. quality trade-off.
Speed and Efficiency: Thanks to architecture optimizations, Claude 3.7 Sonnet is significantly faster and more efficient than earlier models. It’s roughly 20–30% faster in inference compared to the previous Claude generation, which developers will notice as snappier responses, especially in standard mode.
The model also boasts improved throughput and cost efficiency: anecdotal reports cite a 40% reduction in cost for high-volume API usage, partly due to better token utilization and features like prompt caching (discussed later).
Anthropic also improved the model’s energy efficiency at the infrastructure level by about 2×, aligning with their goal of sustainable deployment.
All these mean that using Claude 3.7 via API or cloud service can handle more requests per second and more tokens per minute without breaking the bank or hitting strict rate limits.
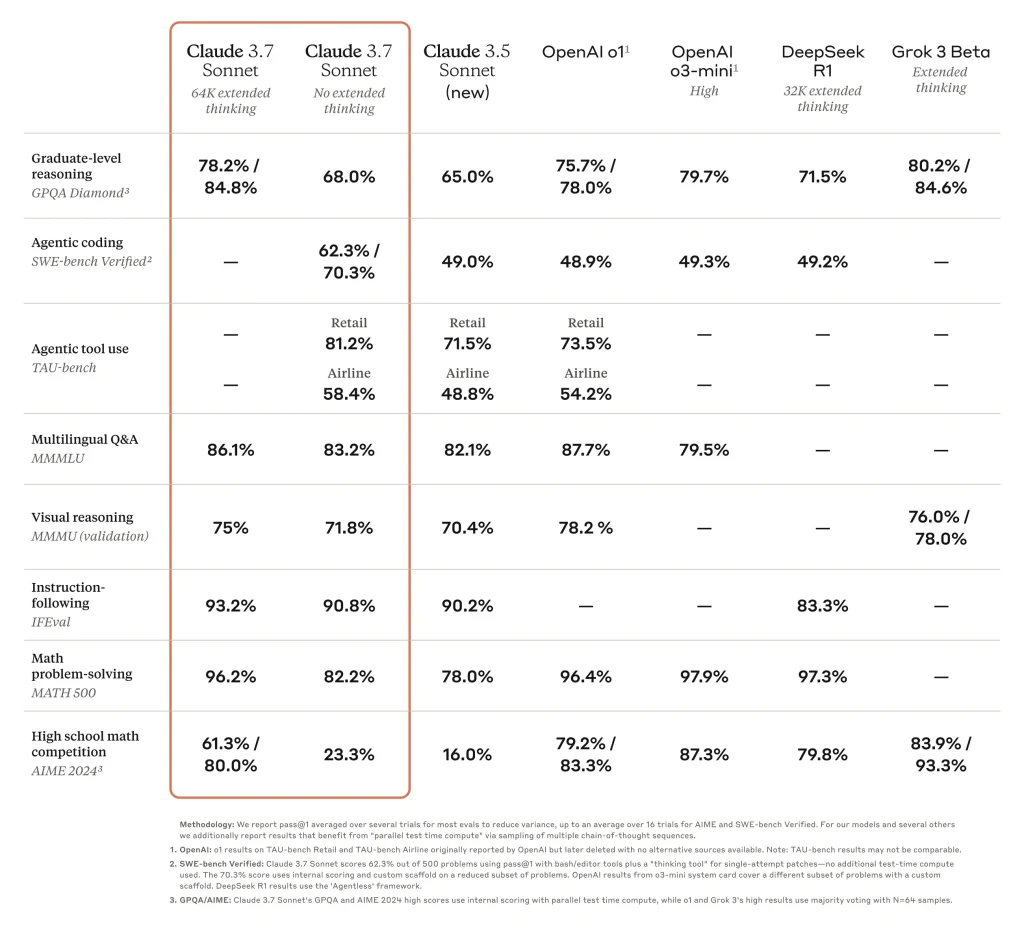
Accuracy and Benchmarks: On quality metrics, Claude 3.7 Sonnet delivers state-of-the-art performance across many domains relevant to developers. It has about a 15% higher accuracy on coding, math, and logic tasks compared to its predecessors, based on Anthropic’s internal evaluations.
In fact, on SWE-bench (Software Engineering benchmark) – a test of solving real-world coding issues – Claude 3.7 achieved 70.3% accuracy in standard mode, a leading result among contemporary models.
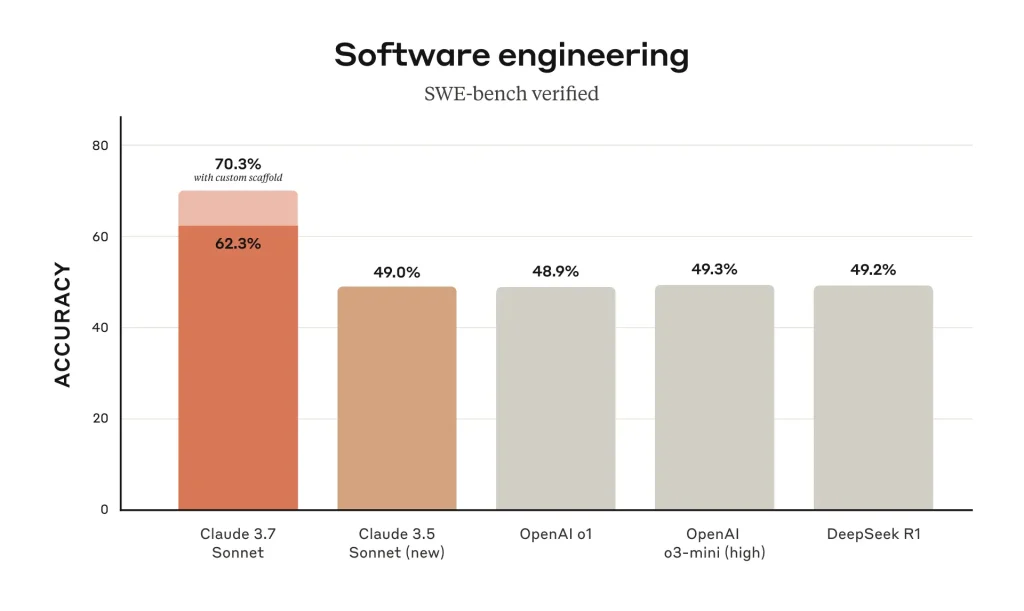
This dramatic jump in coding proficiency translates to more correct solutions and fewer hallucinated answers in day-to-day use. Similarly, on TAU-bench (which tests AI agents on complex, tool-using tasks), Claude 3.7 was noted to attain state-of-the-art results for multi-step reasoning.
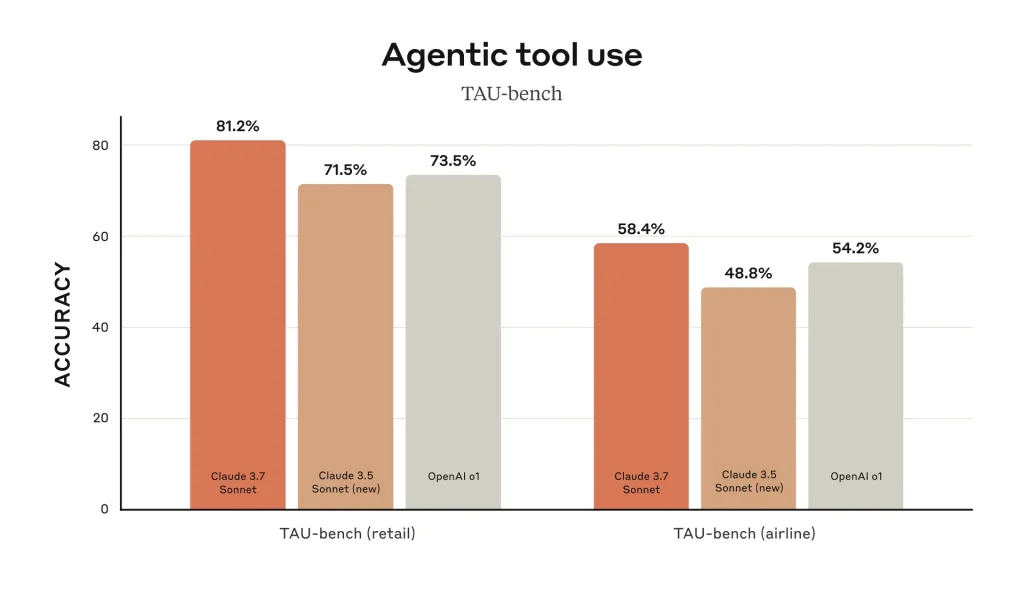
What these benchmarks mean in practical terms is that developers can trust Claude 3.7 to handle not just toy problems or simple Q&A, but to assist with real-world software engineering challenges.
Whether it’s reasoning about large codebases, planning out multi-component software changes, or handling tricky debugging scenarios, this model is equipped to deliver high accuracy and robust performance.
Anthropic’s design philosophy for Claude 3.7 was “frontier reasoning made practical”. Instead of training a model that only excels at academic puzzles or isolated benchmarks, they optimized Claude 3.7 for real-world use cases that businesses and dev teams face.
This includes messy, multi-part tasks like understanding existing code, making incremental improvements, following complicated instructions, and integrating with tools.
The architecture’s hybrid reasoning nature also contributes to reliability – by making its thought process transparent (in extended mode) and allowing developers to audit the reasoning, Claude 3.7 fosters trust in its outputs.
In summary, the model’s architecture and performance enhancements directly benefit developers by providing a fast, context-aware, and highly accurate AI coding assistant.
Use Cases for Developers
Claude 3.7 Sonnet shines in a variety of software development scenarios. Here we outline the top use cases for developers, along with examples of how the model can be applied in each:
- Code Generation – Turn natural language specifications into code. Claude 3.7 excels at writing code in multiple programming languages given a description of desired functionality. For example, you can prompt it with “Implement a function to merge two sorted lists in Python” and it will generate a clean, well-structured Python function for you, often with explanatory comments. It’s capable of producing code snippets, entire functions or classes, and even simple applications. The model’s understanding of programming concepts and libraries means it can suggest idiomatic code and even impose architectural patterns if asked (e.g. “generate a React component for a login form”). This dramatically speeds up boilerplate coding and allows developers to focus on higher-level design. In Anthropic’s internal tests, Claude 3.7 was noted to produce production-ready code that often adhered to good design principles.
- Bug Fixing and Debugging – Identify and fix issues in existing code. Developers can provide Claude with code that isn’t working as expected (and even include error messages or failing test outputs), and ask for help diagnosing the problem. Claude 3.7 can analyze the code logic, pinpoint bugs, and suggest corrected code. It acts like a tireless pair programmer that combs through your logic to find edge cases or mistakes. For instance, “Why does this function return null for input X? Here’s the code: […]” could lead Claude to explain the bug (maybe a missed condition or a variable scope issue) and propose a fix. Because Claude 3.7 maintains awareness of the entire code context, it’s effective at debugging across multiple files – you can paste in several related source files and ask it to locate the issue. Anthropic’s Claude Code tool was built around this capability: describe a bug or paste an error, and Claude will analyze the codebase to implement a fix.
- Test Generation – Automatically write tests for your code. Writing unit tests or integration tests can be time-consuming. Claude 3.7 Sonnet can generate test cases given the code (or a description of expected behavior). For example, “Generate Jest unit tests for this React component” or “Given the following function, write PyTest cases to cover edge cases”. The model will output test code that calls the functions with various inputs and checks expected outputs. It can even create test-driven development (TDD) style interactions: you describe the functionality, Claude writes tests first, then you have it implement the code until all tests pass. Early users reported that Claude could handle writing tests and even doing complex refactoring in a single pass, cutting down what used to be 45+ minutes of work into a few minutes. This capability not only speeds up development but can improve code quality by ensuring new code comes with coverage.
- Technical Documentation & Comments – Explain code and generate documentation. Claude 3.7 is very useful for creating documentation, whether it’s docstrings, API docs, or high-level technical summaries. You can ask it to summarize a codebase or module, and it will produce an overview of what the code does, key classes and functions, and how they interact. For instance, “Explain what the following Java class does and how to use it in a project”. It can also produce usage examples. Likewise, you might use it to generate inline comments: “Add comments to this function to explain each step.” The model’s extended context window means you can feed in a lengthy source file or multiple files; Claude will still be able to reference details from the entire content when producing documentation. Developers have used Claude to automate writing README sections, document API endpoints, and even draft release notes. By delegating the rote documentation tasks to the AI, engineering teams can save time and ensure more consistent, thorough docs.
- Codebase Analysis and Summarization – Understand large codebases or perform impact analysis. With the ability to handle hundreds of thousands of tokens, Claude 3.7 Sonnet can ingest a large repository or a set of files and answer questions about them. This is like having an AI software architect who read your entire project. For example: “Summarize the architecture of this project and list the main responsibilities of each module.” Or “Find all the places where we call database X and suggest how to refactor them to use database Y instead.” Claude can maintain a mental map of the codebase, which means it can answer broad questions (architecture, data flow) as well as specific ones (where a particular function is used, what the impact of a change would be). One of the big advantages is being able to ask questions in natural language instead of manually searching through code. This use case is enhanced by integration features: Claude can connect to your GitHub repository (via Claude.ai’s GitHub integration or third-party tools) to fetch the latest code and then help with analysis. Essentially, it brings a deep understanding of your unique code context, acting as a smart assistant for large-scale code maintenance and review tasks.
In real-world developer teams, Claude 3.7 Sonnet can function as an AI pair programmer and assistant throughout the software development lifecycle.
For example, during planning it can brainstorm solutions or create design docs; during implementation it writes and reviews code; during testing it generates test cases; and post-release it can help with logs analysis or patch generation.
Its strong agentic capabilities (when used with tools like Claude Code) even allow it to execute commands, run tests, or deploy code as directed.
Prompt Example – Code Generation:
**User prompt:**
“**System**: You are an expert Python developer AI who writes clear, efficient code.
**User**: I have two sorted lists of integers. Please write a Python function called `merge_sorted_lists` that merges them into one sorted list without duplicates. Include comments explaining each step.”
In this prompt, we set a system role indicating Claude’s persona (expert Python developer) and then ask the user’s question. Claude 3.7 might output the Python code in a markdown block, for example:
def merge_sorted_lists(list1, list2):
# Initialize pointers for both lists
i, j = 0, 0
merged = []
# Loop until one list is exhausted
while i < len(list1) and j < len(list2):
if list1[i] < list2[j]:
# Add smaller element if not a duplicate
if not merged or merged[-1] != list1[i]:
merged.append(list1[i])
i += 1
elif list2[j] < list1[i]:
if not merged or merged[-1] != list2[j]:
merged.append(list2[j])
j += 1
else:
# If both elements are equal, add one and skip duplicate
if not merged or merged[-1] != list1[i]:
merged.append(list1[i])
i += 1
j += 1
# Append remaining elements from list1
while i < len(list1):
if not merged or merged[-1] != list1[i]:
merged.append(list1[i])
i += 1
# Append remaining elements from list2
while j < len(list2):
if not merged or merged[-1] != list2[j]:
merged.append(list2[j])
j += 1
return merged
(The above is an example of the kind of output Claude can produce for a code generation task.)
As shown, Claude included helpful comments and ensured no duplicates in the merged output. This demonstrates how Claude 3.7 Sonnet for developers can reduce the grunt work in coding tasks and serve as a reliable co-developer. Each of the use cases above can similarly be unlocked with the right prompts and integration, which we’ll explore next.
Integration Workflows
One of the strengths of Claude 3.7 Sonnet is its flexible integration options. Developers can access and deploy Claude 3.7 through various means – from direct API calls in their code, to command-line interfaces, to cloud platform services, and even inside popular IDEs like VS Code. In this section, we’ll cover how to use Claude 3.7 Sonnet via:
- Anthropic API and SDKs (direct integration into your applications)
- Command-Line Interface (Claude Code) and Tools
- Cloud Platforms (AWS, GCP, etc.)
- IDE Extensions (such as Visual Studio Code)
Each method has its advantages, and you can choose the workflow that best fits your development environment or deployment scenario.
Using the Claude API and SDKs
The most direct way to leverage Claude 3.7 is through the Anthropic API, which allows programmatic access to the model. Anthropic provides SDKs in popular languages (Python, TypeScript/Node.js, etc.) to make integration easier. Here’s how you can get started:
Obtain API Access: Sign up for an Anthropic account and get an API key (from the Claude developer console). Depending on your usage, you might start on a free or paid tier. The API is pay-as-you-go with $3 per million input tokens and $15 per million output tokens for Claude 3.7 Sonnet.
Install the SDK: For example, in Python, you can install the official Anthropic SDK via pip. In your environment run: pip install anthropic This provides a client library to easily call Claude. In Node.js/TypeScript, a package like @anthropic-ai/sdk or similar can be used (Anthropic’s AI SDK).
Make an API Call: Using the SDK, you create a client with your API key and then send a prompt to Claude. Claude’s API uses a chat-style format. Here’s a code snippet (Python) demonstrating a simple call:
import os
import anthropic
# Set up API client
api_key = os.environ.get("ANTHROPIC_API_KEY", "<your_api_key_here>")
client = anthropic.Client(api_key=api_key)
# Define your prompt and optional system message
system_message = "You are a knowledgeable AI coding assistant."
user_prompt = "Explain the difference between a stack and a queue data structure."
# Send the request to Claude 3.7 Sonnet
response = client.completions.create(
model="claude-3-7-sonnet-20250219", # specify Claude 3.7 model
max_tokens_to_sample=500, # limit the response length
temperature=0.7, # control creativity
prompt=f"\n\nHuman: {user_prompt}\n\nAssistant:",
# Alternatively, using the newer chat format:
# messages=[{"role": "system", "content": system_message},
# {"role": "user", "content": user_prompt}]
)
print(response.completion)In this snippet, we’re using the Anthropic client’s completion method. We specify the model ID for Claude 3.7 Sonnet (including the version date, e.g., 20250219), set a max_tokens_to_sample (to avoid extremely long outputs), and provide a prompt.
Anthropic’s API expects the prompt in a specific format – here using the older method of prepending "Human:" and "Assistant:" labels. Newer SDK versions support a structured messages list (similar to OpenAI’s format) with roles: system, user, assistant.
You can include a system prompt to prime Claude’s behavior (as shown above with a coding assistant persona).
The API response will contain Claude’s generated answer, which we simply print. Tip: Use the temperature parameter to adjust randomness (0 for deterministic outputs, higher values for more varied responses).
Also, consider using stream=True (if supported in the SDK) to stream the response tokens incrementally – useful for very large outputs so you can start processing or displaying them as they come.
Handle the Response: Once you get the response, you can extract the text and incorporate it into your app. In a chat app, you’d display it to the user; in a coding tool, you might save the code to a file, etc.
Always implement error handling – the API might return errors if you hit rate limits or if the content violates policy, so be ready to catch exceptions or HTTP 429/400 responses.
Maintain Context (if needed): For multi-turn conversations, you’ll want to send the conversation history in each request.
This means appending the latest user query and the assistant’s last answer to the messages list or prompt for the next call. Claude 3.7’s large context window is very forgiving, but keep an eye on the token count if you have a long dialogue or are including large code files as context.
Using the API directly gives you maximum flexibility – you can integrate Claude into custom applications, backends, chatbots, or CI/CD pipelines. The SDK handles the HTTP calls and streaming for you. Remember to secure your API key and follow usage policies.
Command Line and Claude Code CLI
Anthropic introduced Claude Code alongside Claude 3.7 Sonnet – a command-line tool that brings the AI assistant directly into your terminal. This is extremely useful for developers who prefer working in the shell or want to automate coding tasks.
Claude Code allows you to converse with Claude and have it act on your local codebase: it can read files, make edits, run tests, and even commit changes to git, all through a natural language interface.
Getting Started with Claude Code: It’s distributed via npm. Ensure you have Node.js 18+ installed, then run:
npm install -g @anthropic-ai/claude-code
This installs the claude CLI globally. After that, navigate to a project directory and simply start Claude:
cd /path/to/your/project
claude
On first run, it will prompt you to log in (a web browser will open to authenticate your Anthropic account). Once logged in, you’ll see a welcome message in your terminal (as shown in the figure above) for the Claude Code research preview. Now you have a conversational agent in your terminal. You can type instructions or questions, and Claude will respond in-line.
What Claude Code Can Do: It’s more than a chat – Claude Code has the ability to execute certain actions:
- Read & Modify Files: You can ask, “Open
app.pyand refactor thecalculate()function to use memoization.” Claude will display the changes it proposes, and with confirmation, apply them to the file. - Generate Code: “Create a new file
utils.pywith a helper class for logging.” Claude can create the file and populate it with code. - Run Commands: Claude can run your test suite or other shell commands if you ask (e.g., “Run
npm testand tell me if anything fails”). It uses a controlled environment for running commands. - Search the Web: In some configurations, Claude Code can even browse documentation or perform web searches to gather information (using Anthropic’s tool-use APIs).
- Git Integration: It can
git add/commitchanges, or open pull requests. For example: “Commit the changes with message ‘Refactor calculation logic for efficiency’” – Claude will stage files and create the commit as instructed.
All these agentic capabilities mean you can delegate a surprising amount of development workflow to Claude via the CLI. Early testers have reported it’s invaluable for tasks like test-driven development (Claude writes tests, you approve, it writes code until tests pass), debugging tricky issues by explaining logs, and large-scale refactoring where it systematically goes through many files.
IDE Integration (VS Code and more): If you prefer a graphical interface, Anthropic has provided a Visual Studio Code extension for Claude (beta) that interfaces with Claude Code. By installing the Claude VS Code extension from the marketplace, you get a sidebar chat in VS Code powered by Claude 3.7 Sonnet – no terminal required.
This extension allows the same kind of interactions: ask questions about your code, apply fixes, generate new code files, etc., all within VS Code’s UI. It basically brings the Claude Code assistant into an IDE, which is great for developers who want an AI pair-programmer alongside their editor.
(There are also community-driven extensions, like Continue or Claude Coder, that integrate Claude 3.7 into VS Code, but Anthropic’s official extension ensures first-class support.)
Beyond VS Code, Claude has appeared in other developer tools:
- GitHub Copilot Chat – Microsoft integrated Claude 3.7 Sonnet into Copilot’s chat for some tiers, meaning if you’re a Copilot user, you might actually be getting Claude’s assistance in VS Code or Visual Studio. This shows Claude’s strength as a coding AI, being used behind the scenes in popular tools.
- Cursor & Other AI Editors – Tools like Cursor (an AI-enabled code editor) have built-in Claude 3.7 Sonnet support. For instance, Cursor allows free usage of Claude 3.7 for coding assistance by selecting it as the LLM model in their settings. Similarly, a new editor called Trae offers Claude 3.7 integration for free. These specialized IDEs are leveraging Claude’s capabilities to provide smart code completion, explanations, and more.
- Enterprise Integrations – Claude 3.7 is also available in platforms like Databricks (for building AI-assisted data/ML workflows in notebooks). It can even be used inside SQL queries on Databricks, illustrating the flexibility of integration.
Cloud Platform Integrations (AWS, GCP, etc.)
If you prefer not to handle the model API keys and infrastructure yourself, you can access Claude 3.7 Sonnet via major cloud providers and their AI services:
- Amazon Bedrock: Claude 3.7 Sonnet is offered as one of the foundation models on AWS’s Bedrock service. With Bedrock, you can simply call Claude through AWS SDKs or the console without a separate Anthropic account (AWS handles the billing per usage). In Bedrock’s interface, you can toggle the model’s extended reasoning mode with a switch and adjust settings like max tokens and temperature. Bedrock also integrates Claude into tools like Amazon Q (an AI assistant for developers on AWS). If you’re already using AWS for your infrastructure, this can be a convenient route. For example, you could use AWS Lambda or SageMaker endpoints with Claude 3.7 for serverless deployments of an AI-backed feature. The AWS News Blog highlights that using Claude via Bedrock allows easy scaling and that Claude is ideal for “advanced coding workflows” on AWS.
- Google Cloud Vertex AI: Google Cloud partnered with Anthropic to offer Claude models on Vertex AI. Claude 3.7 Sonnet is available in Vertex’s Model Garden with generally available 200k context support. You can invoke it through Vertex’s API or within a Vertex AI Notebook. The advantage here is integration with Google’s ecosystem – for instance, you can feed Claude data from BigQuery or have it work with files in Cloud Storage, all within Google’s secure environment. One caveat: as of GA, Vertex might not expose the extended thinking toggle (some partner platforms run Claude always in standard mode), but you still benefit from the underlying model strengths. For developers, using Vertex AI means you can manage Claude through GCP’s SDK, use Google’s quota system, and log/monitor usage with Cloud Monitoring.
- Others (Snowflake, Databricks): Enterprise platforms are also integrating Claude. Snowflake’s Cortex AI announced support for Claude 3.7, enabling SQL and DataFrame operations to call Claude for analysis or generating code within a Snowflake environment. Databricks, as mentioned, provides Claude 3.7 as a native model you can query in notebooks or in their unified AI API. This is great for data scientists wanting to use Claude for data analysis or to build AI agents that interact with enterprise data. If your team uses these platforms, it can be as simple as loading the model from the marketplace and using it with a few lines of code – no separate deployment needed, and you inherit the platform’s security & governance features.
- Claude Developer Platform: Let’s not forget Anthropic’s own platform – Claude.ai and the Claude Console. Claude 3.7 Sonnet is available to use on Claude.ai’s chat interface (Pro or Team tiers) and via the Developer Console/Workbench. In the Claude Web Workbench, you can test prompts and even generate code to call the API (Anthropic’s console has a feature where after you run an experiment, it can output a snippet in Python or JS that replicates that call). This is a good way to prototype your prompts and parameters before coding them.
Across all these integration methods, the capabilities of Claude 3.7 Sonnet remain consistent. No matter if you call it via direct API, CLI, or a cloud service, you’ll get the same model performance (assuming you have extended mode on when you need it).
The choice comes down to convenience and where you want the AI to live (locally vs. cloud). For quick personal projects, the Claude API or Claude.ai might be easiest.
For enterprise apps, using AWS/GCP integrations might align better with your existing infrastructure. And for daily coding assistance, the CLI or editor plugins bring Claude to you in the most interactive way.
Prompt Engineering Strategies
Getting the most out of Claude 3.7 Sonnet – especially for programming tasks – often hinges on how you prompt it. Prompt engineering is the art of phrasing your queries and instructions to guide the model toward the desired output.
The good news is Claude 3.7 is quite user-friendly: it’s been trained on tons of instructions and code, so it often “knows” what to do with minimal prompting.
However, for reliable and specific coding output, it helps to use some advanced strategies. Here we’ll cover: using system prompts to define role/behavior, chain-of-thought prompting for complex tasks, and formatting tips to get well-structured results.
1. Utilize System Prompts and Roles
Claude supports a notion of a system message (a hidden prompt that sets the context or persona for the AI). By providing a system prompt, you can influence the style and priorities of the model’s response.
For coding, it’s useful to set a role like: “You are a senior software engineer” or “You are an AI assistant specialized in Python.” This can make Claude’s output more relevant. For example, a system prompt might be:
System: You are Claude, an AI coding assistant. You excel at writing clean, well-documented code and explaining your reasoning. Follow best practices and ensure outputs are properly formatted.
This upfront instruction will bias Claude towards more thorough answers, with code comments and adherence to best practices. It essentially injects domain knowledge or style guidelines before the user even asks a question.
Another use of system prompts is to enforce certain constraints or formats. For instance, you can say: “Always answer with only JSON format unless told otherwise” if you want a JSON output.
Or “If the user asks for code, provide only the code in markdown without additional explanation.” Claude will endeavor to follow these rules (within reason). System prompts are a powerful way to “steer” the AI.
Role playing is similar – you can ask Claude to take on a persona. E.g., “You are a Linux terminal. Respond with only shell commands.” This can be handy to get specific formats (like simulating a bash session).
In Anthropic’s API, the system field is where you put such instructions. In a conversational prompt, you can just prefix it as I did in the example above.
2. Chain-of-Thought and Step-by-Step Reasoning
Claude 3.7’s hallmark feature is extended thinking, which is effectively an internal chain-of-thought. But even without toggling extended mode, you as the prompter can encourage the model to reason things out stepwise by explicitly prompting it to do so.
This is known as chain-of-thought (CoT) prompting. The idea is to get Claude to “think out loud” for complex tasks, which often improves accuracy.
Simple way: just say “Think step-by-step” in your prompt. For example:
User: The function is producing incorrect results for certain inputs. Think step-by-step about what the function is supposed to do, identify potential issues, and then provide a corrected version.
By including “Think step-by-step”, you signal Claude to break down the problem. In many cases, Claude will then output an explicit reasoning process followed by an answer. If you want to see the reasoning, you might ask it to format it clearly (like starting its answer with “Reasoning: …” then “Solution: …”).
Anthropic recommends that if you want Claude to engage in reasoning, you must ask it to produce the reasoning in the output. Otherwise, if you say “think internally but only show the final answer,” the model might skip the reasoning entirely.
So it’s better to have it print the reasoning and then the final answer. This transparency can be useful for debugging why it gave a certain answer too.
For more controlled prompting, you can guide the chain-of-thought. Instead of just “think step-by-step,” outline the steps you expect. E.g.:
“User: Explain how this algorithm works. First, outline the steps in simple terms as bullet points. Then, provide a more detailed explanation for each step with references to the code.”
This way, Claude will produce a structured answer because you basically handed it a blueprint of the format. You can similarly prompt a stepwise approach for solving problems: “First, analyze the problem. Second, outline a plan.
Third, write the code implementing the plan. Lastly, test the code with an example.” The model will likely follow this sequence, which ensures it doesn’t jump straight to coding without planning (common in complex tasks).
Extended Thinking Mode: If you have access to the extended thinking feature (via API or Claude’s console with the reasoning toggle), you can rely on that for chain-of-thought. When extended mode is on, Claude will automatically engage its internal reasoning and often output it if supported.
For instance, in Claude’s own UI or some playgrounds, you might see it print a stream of reasoning (like an “assistant is thinking…” log) followed by the final answer. In API usage, you can capture the reasoning text if you use the relevant parameters (Anthropic’s API has a way to return the reasoning trace).
This is advanced, but the net effect is you get a more robust answer since the model took the time to double-check itself. One caution: extended thinking will use more tokens and be slower; use it when it’s worth the trade-off (difficult problems).
3. Output Formatting Tips
When it comes to code or technical content, formatting is key. Claude 3.7 generally follows instructions well if you specify an output format. Here are some tips to get nicely formatted outputs:
Ask for Markdown: If you want the answer in markdown (which is great for copying code, as it will likely put it in code blocks), say so. e.g., “Respond in Markdown format.” Claude will then use markdown for code, lists, etc. Many platforms (Stack Overflow, GitHub, etc.) prefer this.
Use Code Fences: Explicitly instruct Claude to put code in triple backtick fences and to specify the language. For example: “Provide the code inside “`python code blocks.” This way, syntax highlighting will work when you view it, and you can copy-paste easily. Claude usually does this by default when giving multi-line code, but the reminder helps avoid cases where it might give code in plain text.
Structured Answers: If you expect a complex answer (like multiple pieces of output), you can use headings or delimiters in your prompt to guide it. For instance: “Output the result as: 1) Summary of the issue, 2) Suggested Code Fix, 3) Additional Notes.” Numbered or bulleted formats often make Claude structure its answer clearly. You can also request formats like JSON or XML if you need machine-readable output (Claude is quite good at following JSON schema when asked).
Limit Unwanted Text: Sometimes you want just the code and nothing else. You can say: “Only show the code, no explanation.” Or conversely, “Explain your solution in detail and then show the code.” Setting these expectations helps ensure the output isn’t too verbose or too sparse for your needs.
Use XML/Tags for Hiding Reasoning: A pro tip from Anthropic’s docs is to use custom tags to separate reasoning from answers. For example, you can prompt:
<thinking>Think about the problem step by step and show your reasoning here.</thinking>
<answer>Provide the final answer or code here without including the reasoning.</answer>Claude will then ideally fill in those sections appropriately. You can later parse out or ignore the <thinking> part. This is useful in applications where you want to log the AI’s reasoning (for audit or curiosity) but only show the user the final answer. It leverages the model’s ability to follow format instructions strictly.
Few-Shot Examples: If formatting is crucial (say you need an exact style of comment or a specific template), provide an example in the prompt. For instance: “Here is how I want the function documented:” then give a short dummy example. After that, ask Claude to do the same for your target function. Claude 3.7, with its large context, can take in quite a few examples (few-shot learning) to adapt its output style.
By applying these prompt engineering techniques, you can significantly improve the reliability and usefulness of Claude’s outputs. The model is quite capable, but a well-crafted prompt ensures it doesn’t misinterpret your request.
Always remember that you can iterate: if the output isn’t what you wanted, refine the prompt with more guidance or try rephrasing. Claude 3.7 tends to respond well to iterative refinement – it doesn’t get “stuck” easily, and will follow new instructions to adjust previous answers if you point out an issue.
Deployment and Reliability Considerations
When using Claude 3.7 Sonnet in production or team settings, developers must consider aspects like rate limits, safety constraints, error handling, and cost management. Anthropic has designed Claude with a focus on reliability and safe usage, but it’s important to understand the boundaries and best practices:
Rate Limits and Throughput
Anthropic’s API (and by extension, Claude on other platforms) enforces rate limits to ensure fair use. These limits are typically defined in terms of:
- Requests per minute (RPM) – how many calls you can make per minute.
- Tokens per minute (TPM) – how many total tokens (input + output) you can consume per minute.
- (Sometimes also tokens per day or monthly spending limits for overall usage.)
Your exact limits depend on your usage tier. New accounts start with conservative limits (for example, previous Claude versions allowed ~5 requests/min and ~20k tokens/min on a free tier).
As you use and pay more, you automatically graduate to higher tiers with higher limits (Tier 2, 3, etc., each roughly doubling allowed tokens). You can check your current rate limits in the Claude developer console. If a limit is exceeded, the API will return an HTTP 429 error with a Retry-After header.
For developers, this means you should implement retry logic and maybe some throttling on your side. If you plan to use Claude for large volumes (e.g., processing thousands of documents or handling many concurrent users), consider:
- Batching requests: Group multiple prompts into one request if possible (Claude can handle multi-query prompts in one go, given the large context).
- Using prompt caching: Anthropic provides a feature where you can cache parts of the prompt on their servers so you don’t resend them every time. Even better, they updated the API so that cached prompt tokens don’t count against your input token rate limit for Claude 3.7. This means you can drastically increase throughput when reusing context (like a long document prefix).
- Monitor usage: use the response headers or API metrics to monitor how close you are to limits and adjust dynamically (e.g., slow down sending new requests if you’re near the TPM cap).
Safety Constraints and Content Moderation
Claude 3.7 Sonnet comes with improved safety measures. Anthropic has trained it to more finely distinguish between harmful and benign requests, reducing unnecessary refusals by 45% compared to the previous model.
This is great for developers because it means Claude is less likely to falsely refuse a valid request (for instance, discussing something sensitive in a non-harmful context).
However, it will still refuse or safe-complete if the request violates the usage policies (e.g., asking for disallowed content like extremist material or certain types of personal data processing).
As a developer integrating Claude, you should:
- Be familiar with Anthropic’s usage policy. This outlines what the model is not allowed to do (violence, hate, illicit behavior, etc.). If your app might receive user-generated prompts, you need to either filter those or handle refusals gracefully.
- Handle refusals in UX: If Claude responds with a refusal (usually a polite message like “I’m sorry, I can’t help with that request”), decide how your application will react. Perhaps show an error to the user or offer them a chance to rephrase. Do not try to trick the model into complying – Anthropic’s system monitors such cases and it’s against the terms.
- Use the system message for safety when needed: You can instruct Claude, via system prompt, to be extra cautious or to follow certain compliance rules if your domain requires it (e.g., medical or financial advice contexts). But note, the model has a built-in safety layer that you can’t override to make it produce disallowed content.
Anthropic’s System Card for Claude 3.7 provides details on safety evaluations – including how it handles things like prompt injection, bias, and hallucinations. Of note, Claude 3.7 was tested against prompt injection attacks (where a user tries to subvert the system prompt) and has some resistance to them.
Still, as developers, we should not rely blindly on that – best practice is to sanitize or escape any user-provided content that might be concatenated with system instructions.
Error Handling and Robustness
Even with a great model, things can go wrong or be unpredictable. Here are some reliability tips:
- Time-outs and Long Responses: If you ask Claude to produce a very long output (tens of thousands of tokens) or do an extremely heavy reasoning, the request might take a long time or even time out. Extended thinking mode especially can lead to long processing if you set a huge token budget. In such cases, consider breaking the task into smaller parts. For example, instead of one prompt to “Write a 100-page design document,” maybe ask it section by section. Anthropic recommends using batch processing or chunking for cases where optimal thinking is above 32k tokens, to avoid network timeouts. If you use streaming output, you mitigate some timeout risk as you’ll start getting data while it’s thinking.
- Partial Failures: Sometimes Claude might stop mid-answer (perhaps hitting a max token limit or an intermediate error). If the text just cuts off, you can prompt again like “Please continue from where you left off.” The model will usually continue. In code generation, if it produced half a function, you can feed that back and ask it to complete it.
- Hallucinations: Claude 3.7 is pretty factual, but like all LLMs it can occasionally hallucinate – especially about nonexistent library functions or API endpoints. When using it as a coding assistant, always validate critical outputs. For example, if it writes some code using a library, double-check that the functions exist in that library version. The model’s knowledge cutoff is November 2024, so it might not know about very new libraries or changes after that date. Unit tests and code review are your friends; Claude can speed you up, but it’s not infallible.
- Multi-turn consistency: In a long conversation, sometimes the model might forget or slightly contradict something it said earlier (though with 200k context, forgetfulness is much less). If you spot an inconsistency, it helps to remind Claude of the fact in your next prompt. Like, “Earlier you said X, please keep that in mind and do Y.” Because Claude 3.7 was trained to follow instructions and maintain coherence, it will correct course when nudged.
Logging Claude’s outputs (with user consent if needed) is useful for debugging. If it makes a mistake or something odd happens, having logs helps reproduce and report issues to Anthropic if necessary.
They continuously update models (Claude 3.7 might have minor version improvements or a Claude 4 in the future), so giving feedback can be valuable.
Cost Efficiency
Using a powerful model with large context can incur costs, so developers should be mindful of usage patterns to keep it cost-efficient:
- Token Budgeting: Remember the pricing – $15 per million output tokens. A single large response of 100k tokens would cost $1.50, and including a 100k token prompt costs $0.30. It’s not exorbitant for what you get, but it adds up if you do it often. Therefore, enable extended-long outputs only when needed. If you just need a brief answer, consider constraining
max_tokensto a small number. - Prompt Caching: As mentioned, Anthropic’s prompt caching is a killer feature for cost saving. If you have a large context (say a reference document or codebase) that you use across many queries, use the caching API so you don’t resend it each time. According to Anthropic, this can reduce costs by up to 90% for long prompts and also speed up responses by ~85% since the model isn’t re-processing the same text over and over. Essentially, you pay a one-time cost to cache, and then cache reads are much cheaper.
- Efficient Tool Use: If you use Claude’s function calling or tool-use features, take advantage of token-efficient mode where available. Anthropic introduced a mode where tool-related outputs (the “thoughts” and function JSON) are optimized to use fewer tokens. Early users saw around 14% average reduction, up to 70% in some cases. Less tokens for overhead = lower bill.
- Monitoring and Limits: Set up quotas if possible. For example, on Claude’s team accounts you can sometimes set a daily limit to avoid surprise bills. At minimum, implement usage tracking – log how many tokens each request used (the API returns counts). This helps identify if some feature or user is consuming too much.
- Choosing the Right Mode: Use Standard mode vs Extended thoughtfully. Extended thinking consumes output tokens for the reasoning process (which you pay for). If a task doesn’t genuinely need deep reasoning (e.g., a simple regex generation), run it in standard mode to save time and tokens. Conversely, if a task is complex, using extended mode might actually save cost overall by getting a correct answer in one shot rather than multiple attempts.
Finally, Anthropic’s pricing is stable for Claude 3.7 (same as previous Sonnet model) and they even introduced a Max Token Plan for enterprises who need the 200k context regularly.
If you’re in a large org, talk to Anthropic sales about enterprise plans which could offer bulk pricing. For individual devs and small teams, the pay-as-you-go model with tiered rate limits should suffice – just keep an eye on usage as you scale up your application.
Conclusion
Claude 3.7 Sonnet represents a significant leap forward for AI assistants in software development. By combining lightning-fast responses with the ability to engage in deep, step-by-step reasoning, Claude 3.7 serves as a versatile tool that can adapt to a developer’s needs in real time.
Over the course of this guide, we’ve seen how its hybrid architecture and massive context window make it adept at understanding and generating complex code, all while giving developers control over its “thinking” process.
In practical terms, integrating Claude 3.7 Sonnet into your workflow can dramatically improve productivity for dev teams. Routine tasks like writing boilerplate code or documentation can be offloaded to the AI, freeing humans to focus on design and critical thinking.
More impressively, previously arduous tasks – such as comprehending a huge legacy codebase or planning a large refactor – become easier with Claude as an AI partner that can summarize and reason about the entire system.
Real-world scenarios already show its value: teams have used Claude to reduce bug fix times, generate full-stack prototypes, and keep projects well-documented with minimal effort.
To quickly recap for those wondering how to use Claude 3.7 for programming in their day-to-day:
Leverage the API and integrations to bring Claude where you work (be it your IDE, cloud platform, or CI pipeline). It’s flexible – from VS Code extensions to a simple HTTP request – so you can incorporate it into existing tools with minimal friction.
Craft clear prompts and harness advanced techniques (system roles, chain-of-thought, etc.) to guide Claude’s output. A little upfront prompt engineering can yield amazingly precise and reliable results, essentially turning Claude into a tailor-made coding assistant for your project.
Keep deployment considerations in mind – plan around rate limits, watch your token usage, and handle the model’s outputs responsibly (with human oversight for critical code). Claude 3.7 is powerful, but the best outcomes come when developers and AI collaborate, each covering for the other’s blind spots.
In conclusion, Claude 3.7 Sonnet for developers is not just a model upgrade – it’s a paradigm shift in AI-assisted programming. It demonstrates that an AI can both answer trivial questions instantly and delve into complex problems with careful reasoning, all in one package.
For development teams, this means having an AI teammate who can pair program, debug, document, and even execute tasks autonomously when integrated with tools like Claude Code.
By adopting Claude 3.7 Sonnet in your dev processes, you’re likely to see faster turnaround on tasks, fewer mistakes, and a new level of insight when tackling tough technical challenges.
As AI continues to evolve, those who embrace these tools early will gain a competitive edge in productivity and innovation. Claude 3.7 Sonnet is a prime example of what modern AI can do – so dive in, experiment with the examples and techniques from this guide, and unlock new potential in your software projects.
Happy coding with Claude! 🚀