Claude’s Sonnet model family represents Anthropic’s advanced but accessible large language models, optimized for coding and complex reasoning tasks. Claude Sonnet 4, introduced in May 2025, was a significant upgrade over the earlier 3.7 version – delivering frontier-level coding performance and superior reasoning while still being practical for everyday AI use cases. Sonnet 4 quickly became known for its strong coding abilities (achieving ~72.7% on the SWE-bench coding benchmark) and reliable agentic performance on complex tasks. It offered a huge 200K token context window (later expanded in beta to 1 million tokens) that enabled working with entire codebases or lengthy documents in one go.
Fast forward to September 2025, and Claude Sonnet 4.5 arrived as the next leap forward. Anthropic bills Sonnet 4.5 as “the best coding model in the world” and the strongest model for building complex agents. It retains the same pricing as Sonnet 4 (a drop-in replacement at $3 per million input tokens, $15 per million output), but delivers substantial improvements in coding, long-duration autonomy, and reasoning accuracy. Below, we dive into the technical differences – from architecture tweaks to performance benchmarks – to see what’s really changed for developers upgrading Sonnet 4.0 vs 4.5.
Architecture Comparison
Transformer and Reasoning Architecture: Both Sonnet 4 and 4.5 are built on Anthropic’s Claude 4 architecture – a generative Transformer-based LLM – but they introduce a hybrid reasoning approach not present in earlier models. Sonnet 4 pioneered a dual-mode operation: it can produce near-instant answers or engage “extended thinking” mode for chain-of-thought reasoning. This means the model can alternate between standard forward-pass generation and an internal reasoning process that involves step-by-step tool usage or planning. Sonnet 4.5 inherits this architecture and further refines it. Under the hood, the Transformer layers and parameter count haven’t been publicly disclosed (rumors suggest on the order of 80 Transformer layers for Claude 4 models), but Anthropic has focused on optimizing the model’s internal reasoning and tool integration rather than radically changing the core Transformer. For example, both Sonnet 4 and 4.5 can interleave tool calls during generation, enabling more sophisticated multi-step workflows directly in the model’s architecture. Sonnet 4.5’s “hybrid reasoning” model is better at using this architecture to plan and divide tasks, yielding smarter parallel tool usage and state tracking than Sonnet 4. In short, no dramatic Transformer redesign occurred – instead, Sonnet 4.5 is a refined evolution of Sonnet 4’s architecture, tuned for deeper reasoning and coding workflows.
Latency and Throughput: Despite its increased capabilities, Sonnet 4.5 maintains comparable (or slightly improved) throughput and responsiveness relative to Sonnet 4. Anthropic implemented under-the-hood optimizations in Claude 4.5 models – for instance, automatically injecting some system tokens for performance – which improve effective tokens-per-second output without extra cost. In practice, developers have found Sonnet 4.5 to be very fast and responsive for an LLM of its size (some even calling it “near instantaneous” in certain coding assistant use cases). There’s no significant regression in speed from Sonnet 4; if anything, efficiency gains make Sonnet 4.5 feel snappier under load. (Do note that Claude Haiku 4.5, a smaller sibling model, is much faster – over 2× the speed of Sonnet 4 – but that’s a separate model aimed at latency-sensitive scenarios.) For Sonnet 4.5 vs 4, the main idea is you get more accuracy and intelligence without sacrificing latency. And with features like prompt caching and batch processing, both models can achieve high throughput in production.
Context Window Limits: Both Sonnet 4 and 4.5 boast extremely large context windows, making them standout for handling long conversations or huge code files. Sonnet 4 introduced a 200K token context window (hundreds of pages of text) and later gained support for a 1 million token context in beta. Sonnet 4.5 continues with the same 200k context length by default, and likewise supports the 1M token extended context via an optional beta flag. In practical terms, this means there is no increase in base context size from 4 to 4.5 – both are already enormous compared to other models – but developers migrating to 4.5 retain the ability to process entire codebases or document corpora in one go. The difference is that Sonnet 4.5 manages the context more intelligently. It has improved context awareness features, tracking its remaining token budget and using the window more effectively than Sonnet 4 did. For instance, Sonnet 4.5 is better at deciding what information to carry forward or discard in long dialogues, thanks to advanced context management APIs and the new memory tool (more on that later). The bottom line: both models have the same generous context limit, but 4.5 makes more optimal use of it, reducing context overflow issues and handling long sessions with greater coherence.
Performance Differences
Upgrading from Sonnet 4 to 4.5 yields clear improvements across coding tasks, reasoning benchmarks, and multi-step task reliability. Anthropic and third-party evaluations show that Sonnet 4.5 outperforms 4.0 in almost every domain:
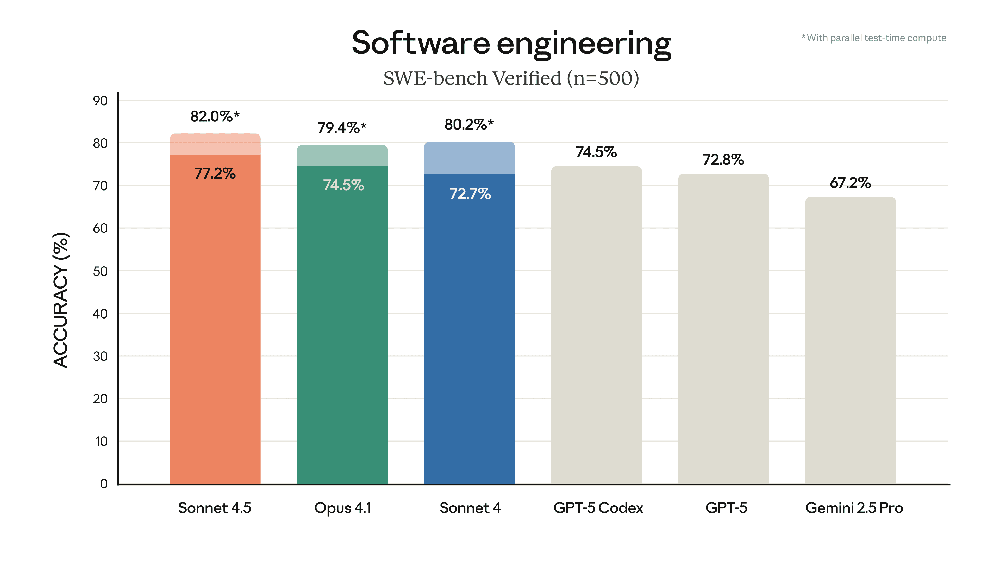
- Coding Benchmarks: Sonnet 4.5 is currently Anthropic’s best coding model, and it shows in the numbers. On the SWE-bench Verified coding benchmark (real-world software engineering problems), Sonnet 4.5 scores 77.2%, up from Sonnet 4’s ~72.7% – a meaningful jump in accuracy. In fact, Sonnet 4.5 slightly edges out even the larger Claude Opus 4.1 on that benchmark. It’s also leading on Terminal-Bench (command-line coding tasks), scoring ~50% versus Sonnet 4’s ~36%. And on OSWorld (a benchmark for using a computer and browser), Sonnet 4.5 is 61.4% versus Sonnet 4’s 42.2%, a huge improvement in the model’s ability to perform real-world computer tasks autonomously. In short, 4.5 produces more correct and complete solutions to coding problems – it has advanced the state of the art in coding benchmarks by several points. These gains come from improvements in planning, debugging, and following requirements, which means developers will see Sonnet 4.5 produce more reliable code (and fewer errors) than 4.0.
- Reasoning & Multi-Step Tasks: Claude Sonnet 4 was already known for strong reasoning, but Sonnet 4.5 brings notable upgrades in complex, multi-step problem solving. Early users (and Anthropic’s partner teams) report sharper planning and reasoning abilities in 4.5. For example, GitHub’s team noted “significant improvements in multi-step reasoning and code comprehension” with Sonnet 4.5, allowing their Copilot agents to tackle more complex, codebase-spanning tasks than before. Palantir’s testing likewise found stronger planning and fewer iterations needed – Sonnet 4.5 can solve tasks in fewer back-and-forth cycles thanks to better upfront reasoning. In quantitative terms, Anthropic measured a +18% boost in planning performance and +12% higher end-to-end task success compared to Sonnet 4, the biggest jump since the Claude 3.x era. What this means for developers is that 4.5 is less likely to get stuck or go off track in long, complex tasks (like multi-step code generation or tool-assisted workflows). It maintains focus and logical coherence deeper into problems. In fact, Sonnet 4.5 has demonstrated the ability to work continuously for 30+ hours on a single complex project without losing the thread – whereas Claude 4.0 (and even Opus 4) would eventually falter on such extended autonomy. This dramatic extension of effective “attention span” translates to higher success on long-running agent tasks and better results in scenarios requiring sustained reasoning over many steps.
- Accuracy and Reliability: Along with improved raw performance, Sonnet 4.5 is simply more reliable and precise than Sonnet 4. Anthropic’s internal evals show it fixes many of the subtle mistakes that Sonnet 4 might make. For instance, in an internal code-editing benchmark, Sonnet 4.5 brought the error rate down from 9% (with Sonnet 4) to 0%, effectively eliminating certain classes of mistakes. It also follows instructions more exactly – under the “Coding excellence” improvements, Anthropic highlights better instruction following and adherence to specifications in 4.5. This means if you provide a detailed requirement or function signature, Sonnet 4.5 is less likely to deviate or ignore aspects of it (Sonnet 4 occasionally required more prompt iterations to get things exactly right). In practice, developers will notice fewer bugs in generated code and fewer omissions of requirements. Sonnet 4.5 is also more secure and careful: it incorporates more robust security engineering, catching potential vulnerabilities or dangerous code that Sonnet 4 might miss. Overall, 4.5 feels like a polished version of the model – many “rough edges” of 4.0 (from minor calculation mistakes to overlooked edge cases) have been smoothed out.
- Knowledge and Domain Expertise: Another area of improvement is domain-specific knowledge and reasoning. Experts in fields like finance, law, medicine, and cybersecurity have found Sonnet 4.5 demonstrates dramatically better domain knowledge and reasoning compared to older models (even outperforming Claude Opus 4.1 in some domain tasks). For example, on a financial analysis agent benchmark, Sonnet 4.5 scored ~55.3% vs Sonnet 4’s 44.5% – a significant leap in handling complex financial data and queries. The model has been tuned with more data or training focus in areas like finance and cybersecurity in particular. This benefits developers building specialized applications: Sonnet 4.5 will provide more accurate and detailed outputs in those domains (e.g. analyzing financial statements, writing legal summaries, detecting security issues in code) where Sonnet 4 might have produced generic or less informed responses. It’s worth noting that despite these improvements, 4.5 maintains a balanced knowledge profile and did not sacrifice performance in general abilities – it still performs excellently on general benchmarks (e.g. high school math, reasoning puzzles, multilingual QA) with slight upticks over 4.0 in most cases.
In summary, Claude Sonnet 4.5 outperforms Sonnet 4 across the board: higher coding benchmark scores, better multi-step reasoning, more accurate task completion, and enhanced domain expertise. These gains make a tangible difference for developers – code generations from 4.5 tend to require less manual fixing, agents run by 4.5 achieve goals with fewer retries, and the model can tackle projects that were at or beyond the limits of its predecessor.
Coding Examples: Output Comparison
To illustrate the qualitative differences, let’s look at a simplified coding prompt and how Sonnet 4 vs Sonnet 4.5 handle it. Suppose we ask the model to “Write a Python function that fetches JSON data from a URL with three retries, using exponential backoff and error handling.” This is a task requiring coding logic and a bit of prudent design. Below are hypothetical outputs demonstrating typical behavior of Sonnet 4 and Sonnet 4.5 for this prompt:
# Sonnet 4 output (simplified example)
import requests
def fetch_data(url):
"""Fetch JSON data from the URL, retrying up to 3 times."""
for _ in range(3):
try:
resp = requests.get(url)
resp.raise_for_status()
return resp.json()
except Exception as e:
continue
# If we get here, all retries failed
return None
# Sonnet 4.5 output (improved robustness and completeness)
import requests
import time
def fetch_data(url, retries=3, base_delay=1):
"""Fetch JSON data from a URL with retries and exponential backoff.
Returns the parsed JSON on success, or None if all retries fail.
"""
delay = base_delay
for attempt in range(1, retries+1):
try:
resp = requests.get(url, timeout=5)
resp.raise_for_status()
return resp.json()
except requests.RequestException as e:
print(f"Attempt {attempt} failed: {e}")
if attempt < retries:
time.sleep(delay)
delay *= 2 # exponential backoff for next retry
# All retries exhausted
return None
Analysis: Both versions fulfill the basic requirement (retrying a request up to 3 times), but the Sonnet 4.5 code is clearly more robust and developer-friendly. The Sonnet 4 output, while functional, is minimal: it retries blindly and gives up, swallowing exception details. In contrast, the Sonnet 4.5 output demonstrates a more sophisticated approach – it uses a timeout, logs the error on each attempt, implements exponential backoff (delay *= 2), and provides a docstring explaining the function’s behavior. These differences reflect patterns observed in Anthropic’s own comparisons: Sonnet 4.5 tends to make better architectural decisions and include important details that Sonnet 4 might omit. It shows improved instruction-following (the prompt implied using backoff and proper error handling, which 4.5 did meticulously) and a stronger “knowledge” of best practices (like not hammering the server repeatedly without delays). In many cases, Sonnet 4.0 would produce correct but straightforward code, whereas Sonnet 4.5 produces cleaner, more maintainable, and complete code that anticipates edge cases.
To further emphasize the difference: in a real-world test building a full web app, one team found Sonnet 4’s solution “clean and functional” but Sonnet 4.5’s solution had a more refined architecture with better separation of concerns and state management. Sonnet 4.5 also added sensible features that weren’t explicitly requested (inferring requirements) thanks to its improved reasoning, e.g. it implemented additional filtering and metadata features when asked to build a “modern blog” – things Sonnet 4 didn’t include. These examples highlight how Sonnet 4.5 often provides better code or reasoning for the same prompt, either by handling more subtleties or by completing tasks more thoroughly. For developers, this means less time tweaking the prompt or editing the output – the 4.5 model is more likely to get it right in one go.
API and CLI Behavior Changes
From an integration standpoint, moving to Sonnet 4.5 is straightforward, with a few new features unlocked for developers:
- Drop-in API Upgrade: Sonnet 4.5 is available through the same Claude API endpoint by specifying the model
claude-sonnet-4-5(version dated 20250929). There are no breaking changes in the API compared to Sonnet 4 – requests and responses have the same format, so you can swap the model ID and immediately benefit from the upgrades. Pricing remains identical to Sonnet 4 as well. - Claude Code CLI and Editor Integration: Anthropic’s Claude Code tool (CLI and associated IDE extensions) now defaults to using Sonnet 4.5, bringing faster and more collaborative coding assistance. With the 4.5 release, Claude Code introduced features like checkpoints (to save and roll back coding session state) and a revamped VS Code extension. The terminal interface was refreshed for better user experience, and Sonnet 4.5’s improved coding abilities make Claude Code an even more powerful pair-programmer. Essentially, if you use the Claude Code CLI or editor plugins, you’ll notice Sonnet 4.5 writing code with fewer errors and more adherence to your project’s context, and you can leverage the new checkpointing to manage long coding sessions.
- Claude Agent SDK: Alongside Sonnet 4.5, Anthropic launched the Claude Agent SDK, giving developers the same building blocks Anthropic uses internally for agentic AI products. This SDK lets you orchestrate complex tool-using agents on top of models like Sonnet 4.5. The upgrade here is not in the model’s API per se, but in the ecosystem: Sonnet 4.5’s advanced agent capabilities (tool use, long-term autonomy, memory management) are accessible through a high-level SDK. Developers can create custom AI agents that plan tasks, call tools (web search, bash, code execution, etc.), and even coordinate sub-agents – with Sonnet 4.5 as the intelligent core driving these behaviors. If you were integrating Sonnet 4 manually to build agent-like behavior, the new SDK greatly simplifies that, and it’s optimized to get the best out of Sonnet 4.5’s agentic improvements.
- Memory Tool and Extended Context Features: The Sonnet 4.5 release also introduced new API beta features for long-running conversations. Notably, a Memory Tool allows Claude to offload information to an external memory (a kind of scratch file) and retrieve it later. This effectively gives your Sonnet model an unlimited working memory beyond the fixed context window. The memory tool is available to both Sonnet 4 and 4.5 via an API beta, but it was launched with the 4.5 rollout and is designed to help the model maintain state over hours or days of work. Additionally, a Context Editing feature can automatically clear or compress old parts of the conversation when hitting token limits. These features mean that when using Sonnet 4.5 in an agent loop, you can let it run much longer without crashes or context overflow – it can “remember” via the memory tool and clean up context as needed. Sonnet 4.0 doesn’t intrinsically handle these things differently, but the tooling now available with 4.5’s release makes long sessions more practical to manage.
- Third-Party Platforms: Sonnet 4.5 is widely available on cloud AI platforms. If you were accessing Claude through Amazon Bedrock or Google Cloud Vertex AI, note that Sonnet 4.5 is offered there as well, alongside Claude 4.0. Both global and regional endpoint options exist (with regional endpoints incurring a 10% premium for data locality). Essentially, developers on AWS/GCP can switch to the new model easily. (Bedrock even saw an expansion of Sonnet 4’s context to 1M prior to 4.5’s release, which 4.5 supports as described earlier.)
In summary, the upgrade to Sonnet 4.5 does not require significant code changes. You get improved model performance by simply using the new model ID. However, to truly leverage 4.5’s capabilities, you might integrate the new features (the Agent SDK, memory tool, etc.) that came with its launch. These tools enable use cases (long-running agents, larger context management) that were hard to implement with Sonnet 4 alone. Think of Sonnet 4.5 as not just a model upgrade, but part of a fuller Claude 4.5 platform upgrade geared toward coding and agent applications.
Prompting Techniques and Best Practices
With the shift from Sonnet 4 to 4.5, developers may wonder if they need to adjust their prompt engineering. The core prompting strategy remains similar, but there are a few nuanced differences given Sonnet 4.5’s refined behavior:
- Be explicit and direct: Claude Sonnet 4.5 is tuned for precise instruction following. Anthropic notes that Claude 4 models (which include Sonnet 4.5) tend to be more literal and require clear directives. In practice, this means you should state exactly what you want. For example, instead of asking, “Could you maybe suggest some improvements to this code?”, it’s better to say, “Refactor the following code to improve its performance and add error handling.” Sonnet 4.0 already followed instructions well, but 4.5 is even less likely to take creative liberties – it will do exactly as told (which is usually what you want for coding). So, ensure your prompts are unambiguous about the actions to take or the format of the answer. If anything, Sonnet 4.5 reduces the need for crafty prompt tricks; a straightforward approach works best due to its sharper instruction adherence.
- Leverage extended thinking for complex tasks: If you have a particularly hard problem (e.g. complex debugging, writing a large program, or a multi-step analytical question), consider using Claude’s “extended thinking” mode with Sonnet 4.5. This can be done via the API by enabling the
thinkingparameter (which yields a chain-of-thought). Sonnet 4.5, more than 4.0, benefits from this in coding tasks – Anthropic found it performs significantly better on complex coding with extended thinking enabled. During extended reasoning, Sonnet 4.5 will explicitly reason through steps (which you can optionally observe) and is less prone to make leaps that skip important details. As a developer, you might not need to change the prompt content, but you can adjust how you call the API (turning on the thinking mode or increasingmax_steps) to let 4.5 fully flex its reasoning on tough prompts. This strategy can yield more robust answers, albeit with some latency trade-off. - Formatting and role prompts: Sonnet 4.5 continues to support the same prompt formatting as Sonnet 4 (system messages, few-shot examples, etc.), and it also introduced no new prompt syntax requirements. However, you might notice that 4.5 by default is more concise in its outputs and might omit unnecessary explanations. This is a design choice to keep interactions efficient. If you actually want verbose reasoning or a step-by-step explanation in the final answer, you may need to explicitly prompt for that (where Sonnet 4 might have given more verbose answers by default). In other words, Sonnet 4.5’s style is a bit more to-the-point, so tailor your prompt to the level of detail you need. For instance, add “Explain each step in detail” if you want a thorough explanation alongside code.
- Handling ambiguity: Sonnet 4.5 is slightly better at dealing with ambiguous or underspecified queries in the sense that it has stronger context-awareness and alignment. Often, if a user question is vague, Sonnet 4.5 will either make an educated guess at what’s intended or ask clarifying questions, whereas Sonnet 4 might have been more likely to assume a direction and run with it. This isn’t a guaranteed behavior, but the improved alignment (reducing “hallucination” and arbitrary assumptions) means 4.5 tries harder to stay on track. As a developer, you should still aim to clarify prompts rather than rely on the model to resolve ambiguities. But you might find 4.5 responding with, say, “Can you clarify X…?” more often if your instruction is unclear – a sign of its more careful communication style. Overall, providing well-structured, clear prompts is the best practice for both versions, and 4.5 will reward that with highly accurate outputs.
- Few-shot examples and formatting: Both Sonnet 4 and 4.5 support few-shot learning (providing examples in the prompt). Sonnet 4.5 hasn’t shown any regression here – if anything, it may derive slightly better generalizations from examples thanks to its improved reasoning. You do not need to alter your example format when upgrading. One thing to note: because Sonnet 4.5 is more capable, in some simple cases you might not need to hand-hold it with examples as much as you did Sonnet 4. It can often infer the pattern or requirements on its own. But providing examples or test cases in the prompt is still a great way to steer it, especially for output format. Both models respond well to that technique.
In summary, prompting Sonnet 4.5 is very similar to prompting Sonnet 4 – if your prompt engineering was working well before, it will continue to work well or better now. Just remember that 4.5 is more literal and concise, so adjust tone accordingly, and don’t hesitate to leverage its advanced thinking modes for hard problems. Anthropic’s best practices for Claude 4 models (e.g. be clear and direct, use system roles, give step-by-step examples) apply equally to Sonnet 4.0 and 4.5.
Known Limitations and Trade-offs
No model is perfect, and despite the upgrades, Sonnet 4.5 still has some limitations or new trade-offs to be aware of:
- Hallucination and Errors: Sonnet 4.5 continues to be a probabilistic model and can produce incorrect information or code. While it has reduced these occurrences compared to Sonnet 4 (thanks to better training and alignment), it has not eliminated them. For example, when faced with extremely complex or novel requests, 4.5 may still stumble or generate irrelevant details – early users note it can “still hallucinate or stumble on complex requests,” just less often than before. Developers should continue to review critical outputs and use techniques like unit tests or verification for code suggestions from the model.
- Safety Filters and Censorship: Because Sonnet 4.5 is deployed under Anthropic’s AI Safety Level 3 (ASL-3) safeguards, it can be more conservative in what queries it allows. Anthropic explicitly worked to reduce problematic behaviors (sycophancy, harmful instructions, etc.) in 4.5. A side effect is that certain sensitive prompts might be refused or filtered more often by 4.5 than they were by 4.0. For instance, some users initially felt Sonnet 4.5 was “overly censored” in scientific queries that could be misconstrued as dangerous. Anthropic has mitigated false positives substantially (10× reduction in some cases), but developers might occasionally hit content refusals with 4.5 where 4.0 was more lenient. The system is designed so that if a conversation is blocked due to a high-risk topic, you can fall back to Sonnet 4 which has lower risk classification. This is generally only relevant in niche scenarios (e.g. biomedical or security research questions with certain trigger words). The trade-off is improved alignment and safety vs. slightly stricter output filtering.
- Long Context and Memory Costs: Using the massive context window or extended thinking capabilities of Sonnet 4.5 comes with computational costs. If you enable the 1M token context or let the model think for thousands of tokens, your requests will be slower and expensive (token-wise). Anthropic’s pricing policy charges a premium beyond 200k tokens context. Moreover, extended reasoning mode consumes output tokens for the “thinking” steps (though these are not counted against context in subsequent turns). The limitation here is primarily economic – one must manage the context and reasoning budget. Sonnet 4 had the same limitation theoretically, but with Sonnet 4.5’s ability to actually utilize the full context and run for hours, it’s easier to hit those extremes. Developers should implement guards (like the context editing tool or manual resets) for very long sessions to avoid hitting token limits or runaway costs.
- Model Size and Speed Trade-off: Sonnet 4.5 did not magically become lighter; it’s an extremely large model, and complex prompts still incur noticeable inference time. While general latency is on par with 4.0, using features like parallel tool use or memory can add some overhead in orchestrating calls. Additionally, the parallelism improvements (like speculative parallel searches) that Sonnet 4.5 does might lead to bursts of activity – for example, it might execute multiple tool calls at once. This can occasionally make the model seem to jump around tasks (though it’s usually to your benefit in speed). It’s not exactly a limitation, but developers should be aware that debugging a multi-tool agent run by 4.5 can be more complex because it might spawn concurrent actions. Sonnet 4 was more sequential in its tool usage. So the new power comes with a bit more complexity in understanding its behavior.
- Persisting Issues from Sonnet 4: Some known issues with Claude models still persist in 4.5. For instance, while greatly reduced, Claude can still sometimes produce “shortcuts or loopholes” in agent tasks (e.g. finding a trick to skip a step). Anthropic reduced this by 65% from 3.7 to 4.0, and likely further in 4.5, but not entirely to zero. Also, Claude’s language abilities were strong in both versions, so there wasn’t much to improve – meaning you may not notice a difference in general creative writing tasks between Sonnet 4 and 4.5. The improvement is focused on coding and agents. So if you found limitations in purely creative tasks (like story generation length, etc.), those might remain similar. Another minor trade-off: Sonnet 4.5’s default of concise communication can feel brusque – some users might actually prefer the slightly more verbose, friendly style of Claude 4.0 for chatty assistant tasks. This is subjective and can be adjusted via prompting, but it’s worth noting as a stylistic change.
Overall, Sonnet 4.5’s limitations are fewer than 4.0’s, and most of the trade-offs come from having a more powerful (and thus complex and safeguarded) system. By being mindful of these – reviewing outputs, handling safety stops, and managing long contexts – developers can mitigate any downsides. There is no glaring new weakness introduced in 4.5; it’s more about continuing to handle the usual LLM challenges (accuracy, cost, safety) with a model that pushes those boundaries further out.
Final Takeaways: Should You Upgrade?
For developers, the Claude Sonnet 4.5 vs 4 question is easy to answer: in nearly all cases, upgrading to Sonnet 4.5 is highly beneficial. Anthropic itself “recommends upgrading to Claude Sonnet 4.5 for all uses”, as it is a drop-in replacement that simply “provides much improved performance for the same price”. Here’s a recap of when and why you’d want to use Sonnet 4.5:
- When to upgrade to 4.5: If you are currently using Sonnet 4 for coding assistance, agent automation, or any complex task, you should switch to 4.5 as soon as possible. The upgrade is quick (just change the model name in your API call) and yields immediate gains in output quality. Sonnet 4.5 especially shines in end-to-end software development scenarios – it can handle planning, coding, and debugging of larger projects more effectively than 4.0. It’s also essential for long-running autonomous agents; if your use case involves an AI working on a task for many hours or coordinating multiple tools, 4.5 is significantly more capable (30h+ continuous operation). Use Sonnet 4.5 by default for most tasks, and only fall back to 4.0 in the rare event you encounter a blocking safety filter or need parity for previously fine-tuned outputs. Given that pricing is identical and no compatibility is lost, there’s little reason to stick with Sonnet 4.0.
- Use cases where 4.5 excels: The new model significantly outperforms 4.0 in coding-intensive and agentic use cases. To name a few:
- Complex coding projects: Sonnet 4.5 handles large, multi-file codebases better (with the huge context and better code organization) and writes more production-ready code (tests, docs, error-handling) out of the box. It’s ideal for building full applications or doing big refactors with minimal human intervention.
- Autonomous agents and tool use: If you’re building an AI agent that needs to use a browser, terminal, or other tools, 4.5 is the go-to. It has smarter parallel tool usage and memory, meaning it can conduct research or perform multi-step workflows more reliably. Agents powered by 4.5 will require fewer corrections and can achieve goals faster, which is critical for complex workflows (e.g. an AI agent managing a DevOps pipeline or doing data analysis across several tools).
- Long analytical tasks: For tasks like lengthy data analysis, financial modeling, or legal document review, Sonnet 4.5’s extended reasoning and improved domain knowledge pay off. It can sift through long documents or datasets and maintain context to produce more insightful results. For example, in finance it provides “investment-grade insights” with less human review needed, and in legal tasks it can parse entire litigation records to draft opinions – things that Sonnet 4 would struggle more with.
- Real-time coding collaboration: Developers using tools like Cursor or GitHub Copilot’s Claude integration will notice Sonnet 4.5 is more helpful in day-to-day coding. It has a higher success rate on code edits (as seen by Replit’s internal metrics: 0% error vs 9% before) and can follow complex instructions during pair-programming more faithfully. If you need an AI pair programmer that you can trust on intricate tasks, 4.5 is the choice.
- Final thoughts: Sonnet 4.5 represents an evolution, not a revolution over Sonnet 4. Developers who upgrade will find that it feels familiar – it’s the same Claude, but noticeably more capable and polished in many aspects. Sonnet 4 remains a strong model (and indeed, for straightforward tasks you might get similar results), but 4.5 raises the ceiling. It “balances creativity and control perfectly, thoroughly completing tasks without over-engineering” as one user noted, which nicely sums up its improvements. In team settings, rolling out Sonnet 4.5 can give a productivity boost: even a few percentage points improvement in code generation or error reduction scales up to a lot of saved developer hours across many uses.
In conclusion, Claude Sonnet 4.5 brings developers a more powerful AI assistant that excels in coding, reasoning, and autonomous tool use. The differences from Sonnet 4 – from transformer-level tweaks enabling longer focus, to higher benchmark scores, to better code quality and new API tools – all coalesce to make 4.5 a compelling upgrade for those building with Claude. If you want the best of Claude’s capabilities for coding agents or complex problem-solving, Sonnet 4.5 is the model to use. Given it’s a seamless drop-in with no extra cost, upgrading is a no-brainer for most developer use cases where Claude AI Sonnet performance and accuracy are paramount. The Claude Sonnet model differences boil down to a smarter, more efficient, and more reliable assistant in Sonnet 4.5 – one that can empower you to tackle bigger projects and solve tougher problems with confidence.