
Claude Opus 4 is Anthropic’s flagship large language model introduced in May 2025 as part of the Claude 4 family. It represents a major step forward in capability and is positioned as “the world’s best coding model” with state-of-the-art performance in software engineering tasks.
Anthropic’s model suite is organized into tiers – historically Haiku (small/fast), Sonnet (mid-tier generalist), and Opus (large frontier model).
Within this suite, Claude Opus 4 sits at the top, designed for the most complex reasoning, coding, and “agentic” tasks, while its sibling Claude Sonnet 4 serves as a faster, cost-efficient model for everyday use cases.
Released after extensive safety and performance refinements, Opus 4 is marketed as a step toward a “virtual collaborator” – an AI that can work alongside developers on complex projects over extended durations.
It builds upon Anthropic’s prior Claude models with significant upgrades in context length, reasoning abilities, and tool use.
In practical terms, Claude Opus 4 enables developers to tackle tasks that were previously impractical for AI, such as refactoring large codebases, executing multi-step workflows autonomously, and analyzing lengthy documents in a single session.
The remainder of this guide provides a deep technical overview of Claude Opus 4’s architecture, capabilities, and usage, with an emphasis on helping developers effectively integrate this model into their projects.
Architecture Overview
Massive Context Window: One of the defining features of Claude Opus 4 is its 200,000-token context window, which dramatically expands the amount of text it can consider at once.
This context size (roughly equivalent to 150–200k words) allows Opus 4 to handle entire code repositories, large knowledge bases, or hundreds of pages of documentation within a single conversation.
In fact, Anthropic reports that with its extended reasoning mode, Claude 4 can effectively manage almost 1 million tokens of context for specialized use cases. This is an order of magnitude beyond most contemporary models (for comparison, OpenAI’s GPT-4 maxes out at 32K tokens).
The benefit for developers is that Claude Opus 4 can maintain long-term conversation state and reference extensive materials without losing track, enabling coherent assistance on long-horizon tasks (e.g. analyzing an entire codebase or a lengthy log file).
However, it’s worth noting that a large context is not the same as infinite memory – using the full 200K tokens can incur substantial latency and cost, so developers should still practice good prompt hygiene (including only relevant information rather than naively dumping huge inputs).
Transformer Scale: Under the hood, Claude Opus 4 remains a transformer-based generative model, albeit scaled up significantly from earlier versions.
Anthropic has not publicly disclosed the exact parameter count, but it’s believed to be on the order of tens of billions of parameters (comparable to or larger than Claude 2, which was ~52B).
Training Claude 4 reportedly involved a massive increase in compute – rumors suggest on the order of 4× more training computation than used for Claude 3’s Opus model.
The architecture is a dense Transformer (not a mixture-of-experts), likely with architectural tweaks to accommodate the long context (e.g. enhanced positional encodings or memory mechanisms).
The tokenization for Claude 4 is similar to previous Claude models: it uses a byte-pair encoding (BPE) scheme with around 100k vocabulary, where each token roughly corresponds to a word fragment or character.
This allows efficient representation of code (where each character can be a token) and text. Notably, the model supports an output length up to 32,768 tokens in a single completion, enabling it to generate very large outputs (such as lengthy code files or detailed reports) without truncation.
Hybrid Reasoning and Memory: Claude Opus 4 introduces a novel hybrid reasoning architecture that lets it switch between fast, near-instant responses and a slower “extended thinking” mode for complex tasks.
In simple terms, the model can dynamically allocate more computation (and even perform chain-of-thought prompting internally) when faced with multi-step problems, but it avoids unnecessary slow reasoning for easy queries.
This is achieved through a dual-mode approach: Opus 4 can produce quick answers by default, or enter a step-by-step reasoning process augmented by tool use when the prompt or a developer’s API settings indicate that deeper analysis is required.
As part of extended reasoning, the model can pause its output, perform intermediate calculations or searches, and then continue – effectively simulating an agentic workflow within a single API call.
In addition to its internal context, Claude 4 also features an improved long-term memory mechanism. When integrated with external storage (via the API’s Files tool or Claude Code’s filesystem access), Opus 4 can write and read “memory files” to persist information across steps.
For example, if working on a complex coding task or an interactive session, it might save key facts or summaries to a file that it can consult later, thus not relying purely on the 200K token immediate context.
This is illustrated by Anthropic’s example of Claude Opus 4 autonomously playing a text-based game for hours – the model created a “Navigation Guide” in an external file to remember important clues as it progressed.
This kind of persistent memory helps the model maintain coherence and avoid forgetting details in very prolonged tasks, significantly boosting performance on multi-step problems that go beyond the context window alone.
Safety and Alignment Architecture: Anthropic’s commitment to AI safety is reflected in Claude Opus 4’s design and deployment. The model is trained using Constitutional AI and reinforcement learning from human feedback (RLHF) to ensure it remains helpful and harmless.
In practice, this means Claude has an internal “constitution” of principles (e.g. avoiding toxic or harmful content, following user intent within ethical bounds) that guide its outputs without needing as many hard-coded rules.
Beyond training, Opus 4 includes multiple runtime safety layers. Anthropic has implemented an external safety classifier and filtering system that evaluates model outputs and can block or alter responses that violate safety policies.
In internal tests, this approach was shown to greatly improve Claude’s resistance to malicious prompts or jailbreak attempts (blocking the vast majority of unsafe requests that would bypass an unfiltered model).
Because Claude Opus 4 is significantly more capable than its predecessors, Anthropic applied their Responsible Scaling Policy at deployment by assigning Opus 4 to AI Safety Level 3 (ASL-3).
This is a precautionary framework for highly advanced models, involving stricter security measures, monitoring, and limited access to ensure the model isn’t misused for dangerous purposes.
(For context, previous models like Claude 3.7 ran at ASL-2, and ASL-4 is reserved for hypothetical near-AGI systems.) Under ASL-3, Claude Opus 4 had additional safeguards: more rigorous testing against risky knowledge domains (like biosecurity or malware), a stronger refusal stance on potentially harmful queries, and constraints such as only being available to vetted users or via managed platforms at launch.
These safety architectures mean that Opus 4 will often err on the side of caution – e.g. preferring to say “I’m sorry, I can’t help with that request” if a prompt is even slightly suspect.
For developers, it’s important to be aware of these alignment behaviors, as they can affect how the model responds (especially if a prompt unintentionally triggers a safety rule).
Overall, Anthropic’s layered safety approach makes Claude Opus 4 one of the most aligned and controlled LLMs, suitable for enterprise and production use where reliability is as important as raw capability.
Model Capabilities
Claude Opus 4’s upgrades in architecture directly translate to stronger real-world capabilities across a range of tasks. Below we break down its key competencies, which make it especially powerful for software development and complex problem-solving:
Reasoning and Coding Proficiency:
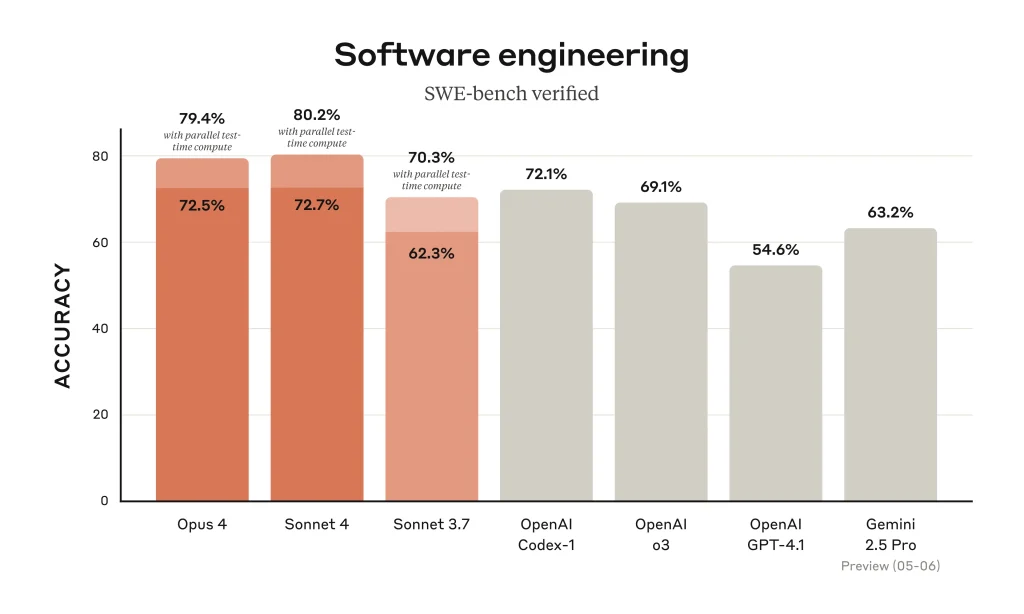
Coding is where Claude Opus 4 truly excels. It has achieved unrivaled performance on software engineering benchmarks, outscoring other leading models by a wide margin. For instance, Anthropic reported Opus 4 reaching 72.5% on SWE-bench (a suite of real-world coding challenges), whereas OpenAI’s latest GPT-4.1 scored only ~54.6% on the same test. Similarly, on a terminal-oriented coding benchmark, Opus 4 leads with 43.2% versus around 25–30% for GPT-4.1 and Google’s Gemini. These numbers indicate that Claude can not only write correct code for typical tasks, but can handle complex, multi-file projects with fewer errors than its rivals. Early users like Cursor and Replit have noted that Opus 4 represents a “leap in understanding large codebases” and can perform precise multi-file edits that were previously infeasible.
In practice, developers can expect Claude to generate code in a variety of languages (Python, JavaScript, Java, C++, etc.), suggest bug fixes, refactor legacy code, and even complete partially written functions or files with remarkable coherence. The model is also adept at “code taste”, meaning it follows best practices and style guidelines when instructed. It can infer the intended functionality from context and produce code that blends in with a project’s existing conventions. Beyond coding, Opus 4 demonstrates strong general analytical reasoning skills. On knowledge-intensive evaluations like GPQA (a graduate-level QA test) and MMLU (Massive Multitask Language Understanding), it scores among the top of all models – for example, around 75%+ on GPQA (significantly above GPT-4.1’s performance) and high-80s on MMLU. This means Claude 4 has a broad and deep grasp of factual knowledge and can perform complex logical reasoning or inference, which is crucial for understanding requirements and ensuring its solutions are correct.
Natural Language Understanding:
Claude Opus 4 exhibits excellent natural language understanding and generation capabilities, making it proficient not just at code but at any task involving plain English (or other languages). It can comprehend complex instructions and subtle prompts, thanks to improvements in its training and alignment. Anthropic notes that Opus 4 produces “natural, human-like prose” and surpasses previous Claude models in writing quality. For developers, this means Claude can be used to generate documentation, explain code in simple terms, write technical guides, or even draft emails and reports with a high degree of fluency. Its large context window also allows it to read and summarize lengthy texts. The model supports multilingual understanding as well – like Claude 3, it can process prompts in multiple languages and even translate or code-switch when needed. For example, one could provide a prompt in Spanish or Japanese and Claude would respond in kind (within the bounds of its training). Its multimodal lineage (in Claude 3 and 4) also means it can interpret image inputs alongside text, although for most developers working via the API, text will be the primary mode. In summary, Opus 4 stands as a strong generalist in NLU/NLG: it’s capable of reading complex technical content, following intricate instructions, and producing well-structured, coherent responses or narratives.
Multi-step Planning and Agentic Behavior:
A standout feature of Claude Opus 4 is its ability to handle long, multi-step tasks with minimal human guidance, essentially functioning as an AI agent. With extended thinking and tool-use enabled, Opus 4 can plan out sequences of actions to achieve a goal and carry them out autonomously. In benchmark tests of autonomous task execution, Claude 4 ran continuously for up to 7 hours without losing focus, successfully performing tasks that earlier models or GPT-4 could not sustain. For example, in one trial it undertook a complex refactoring of a large open-source project (in collaboration with engineers at Rakuten) and was able to keep making coherent, relevant code changes for almost seven hours straight. This demonstrates a kind of “marathon” attention span – whereas previous LLMs would have drifted or forgotten context over such a long session, Opus 4 maintained state and continued to execute the plan.
Internally, the model uses its chain-of-thought to break problems into sub-problems and can decide to use external tools (like running code, searching the web, reading files) at appropriate junctures. The result is a model that doesn’t just react passively to one prompt at a time, but can be more agentic: it can pursue objectives over multiple turns, keep track of intermediate results, and adjust its strategy as needed. This capability is measured in new “agentic” benchmarks (like Anthropic’s TAU – Tool-Augmented Utility – bench), on which Claude 4 ranks at or near the top of all AI systems. For developers, this opens the door to building AI-powered agents (for coding, research, operations, etc.) that rely on Claude for high-level decision-making. Opus 4 is effectively able to plan, reason, and act in a constrained environment – for instance, given a goal to “optimize my database deployment,” it could iteratively analyze the schema, generate migration scripts, run performance tests (via a tool), and refine the solution across many steps.
Support for Structured Outputs and Tool Use:
Claude Opus 4 is particularly good at following instructions to produce structured outputs, which is crucial for developers integrating it with systems. Whether you need JSON, YAML configurations, HTML/Markdown, or other structured text, Claude can adhere to the required format if you clearly specify it. The model’s training on code and data structures makes it less prone to formatting errors compared to generic models. For example, if you prompt Claude with “Output the result strictly as a JSON object with these fields…”, it will usually comply exactly, making it suitable for scenarios where another program will parse the AI’s output. In fact, Anthropic’s API itself harnesses this by enabling function calling via a tool interface: you can define a tool with a JSON schema, and Claude will return a JSON object conforming to that schema when it wants to invoke the tool.
This mechanism ensures that the output is properly structured for the function call. More generally, Opus 4 is adept at producing things like SQL queries, CSV data, or code snippets that fit specific templates – useful for tasks such as generating config files or populating database fixtures. The model’s support for tool use is another game-changer. Out of the box, Claude 4 can integrate with external APIs or tools provided through Anthropic’s new API features. For example, it has a Code Execution ability that allows it to run sandboxed Python code and incorporate the results back into its response. It also can use a web search tool (if enabled) to fetch information on the fly. Anthropic’s Model Context Protocol (MCP) Connector lets developers easily hook Claude up to custom tools or REST APIs by specifying the endpoint – the model will automatically formulate the proper API calls and handle responses. Under the hood, these tools are integrated via special message types; for example, if Claude decides it needs to use a tool, it will output a message with a {"type": "tool_use", "name": ..., "input": {...}} payload instead of normal text. The calling application can detect this and execute the requested action (like running code or querying an API), then feed the results back to Claude, which will continue the conversation incorporating that new data. For developers, this means Claude Opus 4 can be the brains behind complex workflows: it can query databases, call external services, or manipulate files as part of solving a problem, all while keeping the interactions in the context of the conversation. This structured, tool-augmented approach greatly enhances what the model can do, moving beyond static Q&A into dynamic interactions.
In summary, Claude Opus 4’s capabilities span a wide range: it writes high-quality code, understands and generates natural language with ease, excels at long-term autonomous reasoning, and plays nicely with structured data and external tools. These make it a potent assistant for developers and engineers tackling real-world projects.
Developer Use Cases
Claude Opus 4 is a versatile model, but Anthropic has especially tuned it for software development scenarios and complex automation. Here are some of the top use cases for developers, along with how Opus 4 adds value in each:
- Code Generation and Completion: Opus 4 can act as an AI pair programmer, similar to tools like GitHub Copilot, but with a much deeper understanding. Developers can use Claude to generate new code from scratch given a description, complete functions or classes that are partially written, or suggest improvements to existing code. Its strength on coding benchmarks translates to very high accuracy in generated code and fewer hallucinations of non-existent APIs. For example, you might prompt, “Write a Python function to validate an email address using regex”, and Claude will produce a well-structured function with docstrings and comments, often correctly handling edge cases. Unlike simpler code assistants, Claude can also handle multi-file and context-heavy code generation: you can feed it an entire module or a set of related files (within the 200K token limit) and ask for modifications or additions that span across them. It will understand the relationships (e.g. usage of a class in one file and its definition in another) and generate coordinated changes. This is extremely useful for large-scale refactoring or adding a feature that touches many parts of a codebase. Anthropic’s clients reported that Opus 4 could make complex codebase edits “without touching code you didn’t ask it to,” showing a new level of precision in automated coding. Additionally, Claude Opus 4 supports an interactive coding mode via Claude Code, where it can propose edits that appear inline in your IDE. For instance, using the VS Code extension, a developer can highlight a block of code and ask Claude to refactor it; Claude will provide a diff or direct edit suggestion. This speeds up tasks like implementing feedback, cleaning up code, or converting code from one framework to another. In summary, Opus 4 significantly boosts productivity in code generation and completion, effectively automating boilerplate writing and offering intelligent suggestions that align with the project’s style.
- Infrastructure Automation: Claude Opus 4 isn’t limited to application code – it’s also a powerful assistant for DevOps and infrastructure tasks. With its ability to write scripts and understand configuration languages, developers can leverage Claude to manage infrastructure as code or automate cloud operations. For example, you could ask Claude to “Generate a Terraform configuration for a scalable 3-tier web application on AWS”, and it will output a plausible Terraform script defining EC2 instances, load balancers, autoscaling groups, etc. It can also draft CI/CD pipeline configs (like a GitHub Actions workflow or a Jenkinsfile) based on a description of your build/test/deploy steps. Because Claude can use shell and OS-level tools via the Claude Code CLI, it can even be employed to run commands or sequence operations: think of an agent that reads your server logs and then writes a remediation script to fix an encountered issue. Some potential infrastructure automation applications include: generating Ansible playbooks or Dockerfiles, analyzing system logs and summarizing incidents, managing database migrations, and orchestrating routine maintenance tasks. Using Claude’s long context, you can feed in logs or system metrics spanning weeks and ask it to identify patterns or anomalies (e.g. “find when and why did memory usage spike in this period”). It’s important to validate any infra changes suggested by the model (and apply them in a test environment first), but Opus 4 can dramatically reduce the manual effort in writing config code and diagnosing environment issues. Its ability to follow high-level instructions and output structured configuration means even complex setups can be initially scaffolded by the model, with the developer fine-tuning the details. This enables a higher level of abstraction in DevOps – you describe what you want, and the model helps figure out how to implement it.
- Data Analysis and Summarization: With its large context and reasoning skills, Claude Opus 4 can serve as a data analyst or documentation assistant. Developers and data engineers can use Claude to parse and summarize large volumes of text-based data. For instance, you might provide Claude with a raw CSV dump (by converting it to a text table or describing its contents) and ask for insights: “Summarize the key trends in our web traffic data over the past year”. Claude can interpret the data (especially if you provide some schema or explanation) and produce a summary highlighting notable patterns (like seasonal peaks or drops after certain events). It can also generate charts or pseudo-visualizations by outputting structured text that can be fed to plotting tools. Another valuable use case is summarizing technical documentation or research papers. You could give Claude a 100-page API document and ask it specific questions (“What are the main available endpoints and their authentication requirements?”), and it will comb through and provide the answer with references to the document sections. Because of the 200K token context, these queries don’t require chunking the document; Claude can handle it in one go. Real-world examples reported include legal teams using Claude to review lengthy contracts and extract key clauses in minutes. In software engineering contexts, you could feed in the contents of multiple design docs or RFCs and have Claude synthesize them into a single coherent report. When doing data summarization, Claude’s structured output ability is handy – e.g. “Provide the summary as bullet points grouped by theme” or “Output the analysis as a JSON with keys
findingsandrecommendations” will yield machine-readable yet meaningful results. Essentially, Claude Opus 4 can act as a powerful text analyzer that digests large inputs and presents the information in a concise form, saving developers and analysts countless hours. - Prompt Chaining and Agent Orchestration: Developers building AI-driven systems can use Claude Opus 4 as the backbone of more complex prompt chaining or multi-agent setups. Prompt chaining refers to breaking a problem into a series of prompts where the model’s output from one step feeds into the next prompt. Given Claude’s ability to maintain long contexts and produce intermediate reasoning steps (which can be hidden or shown), it’s well-suited to such pipelines. For example, you might design a chain where Claude first formulates a plan, then executes steps of that plan one by one. In the first prompt you ask, “Outline the steps to perform X task,” it provides a numbered plan. Then you feed each step back in sequence, maybe with tool results in between, and Claude completes them. Thanks to the extended context, you can carry all intermediate results in the conversation (up to the huge token limit). This is essentially how agent orchestration frameworks like LangChain or Anthropic’s own Claude Agent SDK operate – using the LLM to reason and make decisions iteratively. Claude Opus 4 shines here because it was explicitly built and tested for long-horizon agentic tasks, keeping consistency over “thousands of steps”. As an example, imagine an agent that handles support tickets: Claude could read a ticket, determine it needs to gather logs (tool call), then analyze the logs (another prompt), then draft a response to the user. Each stage is a chained prompt with the same model. Anthropic demonstrated Claude 4 doing autonomous research by searching the web, reading articles, and writing a comprehensive report – all orchestrated through prompt chaining within the model. For developers, Opus 4 lowers the complexity of such orchestration because the model itself can manage a lot of the state and reasoning that might otherwise require external code. You can also run multiple instances of Claude in parallel (since it’s available via API) to implement multi-agent systems where they converse or work on sub-tasks and then aggregate results. Given its strong results on agentic benchmarks, using Claude Opus 4 as the “brain” of your AI agent will likely yield better reliability and intelligence in completing multi-step workflows compared to less capable models.
Claude Opus 4 Prompt Engineering
Prompt engineering for Claude Opus 4 involves crafting inputs that guide the model to produce accurate, efficient outputs – especially for coding tasks and long contexts.
While Opus 4 is powerful, providing clear instructions and structuring your prompts well is key to getting the best results. In this section, we cover strategies for effective prompt construction, system messages, function/tool calls, and leveraging the 200k token context.
Crafting Prompts for Accurate and Efficient Code:
When asking Claude to generate or modify code, it’s important to be explicit about the requirements and format. Begin by clearly describing the task or problem in plain language, then specify any constraints (language, libraries, style guidelines). For example, a good prompt might be: “Write a Python 3 function is_prime(n) that returns True if a number is prime or False otherwise. The function should be efficient for large n. Include docstrings and comments explaining the logic.” This prompt states the language, function name and signature, expected behavior, and even style elements, which leaves little ambiguity. Claude will typically respond with a properly formatted Python function, complete with a docstring and inline comments as requested. If you have a specific code context or boilerplate, include that in the prompt as a reference. You can paste relevant portions of code above your instruction and say: “Given the above class definition, implement the missing method.” The model will use the provided context to ensure consistency.
It’s also helpful to provide examples in the prompt if you want a certain output format. For instance, to enforce that a function should not print anything, you might add: “Do not use any print statements. For example, if input is 7, is_prime(7) should return True.” Claude then knows both a test case and a constraint. Keep prompts concise but comprehensive – you want to avoid irrelevant information that wastes tokens, but include all details that affect the solution. In coding tasks, specifying the desired output format (just code vs. code plus explanation) is important. If you only want the code, you can say “Important: output only the code and nothing else.” In general, Claude is very good at following these kinds of instructions due to its training; adding phrases like “IMPORTANT” or “Note:” to emphasize requirements (as Anthropic does internally) can help. Finally, for efficiency, avoid extremely long problem descriptions if not needed – although Claude can handle them, shorter prompts yield faster responses and reduce cost. If a prompt is complex, consider whether intermediate prompting (breaking the task into sub-tasks) might be better, but often Claude 4 can manage complex instructions in one go thanks to its reasoning abilities.
Using System Instructions:
Claude’s API supports a special system prompt (system message) that sets the overall behavior of the assistant. This is a powerful tool to steer Claude’s style and role across an entire session. For instance, as a developer you might use a system instruction like: “You are a senior software engineer assistant. Always provide answers with concise explanations and code examples when relevant. Use a polite and professional tone.” By placing this in the system field of the API call, you ensure Claude consistently follows this persona and formatting, without having to repeat these instructions in every user prompt. System instructions have higher priority than user messages, meaning Claude will try to respect them even if the user prompt doesn’t mention them (or in edge cases, to politely refuse if the user asks for something against the system policy). Some effective uses of system prompts in a development context include: setting coding style (e.g. “All Python code should follow PEP8 conventions”), defining the scope of knowledge (“If asked about company-specific APIs, use the documentation provided and don’t guess.”), or establishing boundaries (“Never reveal sensitive keys that might be in the context”).
The Anthropic docs recommend using system messages for high-level guidance and putting task-specific details in the user prompt. In practice, this separation helps keep prompts organized. For example, you could have a system message that defines Claude’s role as a QA tester, and then each user prompt can be a bug description to which Claude responds with a test or analysis. Using system instructions can also help enforce formatting across responses. If you want every answer in Markdown, or to always include certain sections in an output, you can encode that in the system prompt. Keep in mind that extremely lengthy system prompts do count towards the context limit, so don’t put an entire manual in there – but it’s a great place for rules and persona. Claude 4 is quite adept at adhering to a well-crafted system directive. For example, an Anthropic system prompt might look like: “You are Claude, an AI who always thinks step-by-step (showing your reasoning only if asked). You are helpful, honest, and harmless. You refuse any request that involves disallowed content.” (This is similar to Claude’s default hidden persona.) As a developer, you can customize this to your use case.
Handling Function Calling and API Chaining:
As discussed under capabilities, Claude Opus 4 can use tools (functions) via a specialized prompting interface. From a prompt engineering perspective, if you want to harness this, you’ll define the tool’s schema to the API and then simply prompt Claude in natural language to use it when needed. For example, suppose you have an external weather API. You might register a tool get_weather with an input schema like {"location": "string"}. Then you can prompt Claude: “Plan a weekend outing for me. (You have a tool get_weather that gives the weather forecast.)” Claude might output something like: <tool_use name="get_weather" input={"location": "San Francisco"}> as it tries to fetch weather info, which your code detects and handles. From the prompt writer’s perspective, the key is to describe the task normally and let Claude decide when to use the function – you usually don’t have to explicitly tell it “call this function now” (though you can nudge it by mentioning the tool). If the model isn’t using a tool when it should, you might add an explicit hint in the prompt, e.g. “(Hint: You have a tool for weather data.)” or adjust the tool description to be more obvious.
Once Claude gets the tool result, it will incorporate it into the answer. Another scenario is API chaining: getting Claude to produce output that will be fed as input to another API or prompt. In such cases, you want Claude’s output to be both correct and well-formatted. A good approach is to instruct Claude about the next step. For example, “Provide the SQL query, and nothing else, so that it can be executed directly.” If chaining prompts (where Claude’s output becomes the next prompt), you might do something like: “First, output a JSON plan of action, then I will approve it, then you execute.” Claude can follow such staged instructions reliably. Always verify that the function call outputs from Claude match the expected schema – if not, you may need to tweak the prompt or schema. As a tip, when expecting JSON, sometimes telling Claude “format your answer as JSON and validate it” can reduce errors (Claude 4 is pretty good at self-validating JSON). In summary, use natural prompts to let Claude call functions, and be specific when you need a particular format for chaining. The combination of system+user messages can be used here: system prompt can list available tools and their purpose, while the user prompt focuses on the task at hand, thereby separating concerns.
Long-Context Prompt Strategies (200k tokens):
Having a 200K token window is a double-edged sword: it enables huge inputs, but it also requires careful management to use effectively. When working with very large contexts in Claude Opus 4, consider the following strategies. Segment and label the content: If you input multiple documents or a mix of code and text, use section headings or delimiters in your prompt. For example: “<docs>\n[Title: API Spec]\n…content…\n</docs>\n<code>\n…code content…\n</code>\nNow answer the question: …”. By structuring the prompt, you help Claude navigate the content. It’s good at handling structure, and you can refer to parts by label in your question (e.g. “Using the API Spec above, do X”). Provide high-level summaries when possible: If you feed a massive text, and you have a summary of it, include that at the top. Claude can use that summary to guide its focus, potentially saving tokens of reasoning. Anthropic has mentioned that Claude 4 sometimes auto-summarizes its thoughts when they get too lengthy, using a smaller model in the loop, but that is internal.
On your side, you can explicitly say “Summary of Document: … (provided by user)” before the full document. Use the Files API or prompt caching for static context: If you have a giant reference (say a code library or user manual) that you will query multiple times, it’s inefficient to send it in every prompt. Instead, upload it once via Anthropic’s Files API and then refer to it by file ID in the prompt (this feature allows Claude to access it without it counting toward every call’s tokens). Prompt caching is another feature: if your prompt has a large prefix that doesn’t change (like a fixed project description), Anthropic’s API can cache it so you don’t get charged repeatedly. Use these to reduce both cost and latency. Ask the model to focus: With so much information, sometimes Claude might include irrelevant details in the answer. You can counteract this by explicitly instructing what to prioritize. For example: “You have the full log above. Only use the portions related to ‘error 504’ in your analysis.” The model will then concentrate on those parts. Finally, remember that even 200k tokens can be filled faster than you think – don’t stuff the prompt with unnecessary text. If only a portion of a document is relevant, consider extracting that portion before feeding it in. Or use iterative approach: ask Claude to find relevant sections first (it can output section numbers or IDs), then feed those sections in a follow-up. In essence, treat the long context as a powerful resource that still needs management. The payoff is huge: as noted, you can feed hundreds of pages of material and get meaningful results, but always weigh the signal vs noise in what you include. Good long-context prompting will ensure Claude Opus 4 remains efficient and accurate even at maximum context size.
Integration Guide
Claude Opus 4 is available through the Anthropic API and various platforms, making it accessible for integration into your applications, development environments, or pipelines.
In this section, we’ll discuss how to use Opus 4 via the API, what SDKs/CLI tools are available, and tips for embedding Claude into IDEs and workflows.
Using the Anthropic API (Direct Integration): To programmatically use Claude Opus 4, you will typically call Anthropic’s REST API with your API key. Claude Opus 4 (and 4.1) are exposed as distinct model IDs.
For example, as of August 2025 the model identifier for Claude Opus 4.1 is claude-opus-4-1-20250805. You can specify this model in your API requests to get Opus-level responses. Here is a sample using Anthropic’s official Python SDK:
import os
from anthropic import Anthropic
client = Anthropic(api_key=os.environ.get("ANTHROPIC_API_KEY"))
response = client.messages.create(
model="claude-opus-4-1", # Opus 4 (latest version)
max_tokens=512,
messages=[
{"role": "system", "content": "You are a helpful DevOps assistant."},
{"role": "user", "content": "Write a Bash script to back up the /var/logs directory to /backup."}
]
)
print(response.content)
In this example, we create a conversation with a system role and a user question. Claude’s reply (response.content) would be the Bash backup script, likely with an explanation if not told otherwise.
The Anthropic Python SDK simplifies calling the API (under the hood it’s making a POST request to Anthropic’s API endpoint). If you prefer curl or HTTP libraries, the JSON payload would look like:
POST /v1/complete
Authorization: Bearer YOUR_API_KEY
Content-Type: application/json
{
"model": "claude-opus-4-1",
"messages": [
{"role": "system", "content": "You are a helpful DevOps assistant."},
{"role": "user", "content": "Write a Bash script to back up the /var/logs directory to /backup."}
],
"max_tokens_to_sample": 512,
"stream": false
}
Anthropic’s API supports both synchronous completions and streaming responses (similar to OpenAI’s APIs). Setting stream=true in the request will stream the completion incrementally, which is useful for long outputs so your application can start processing before the entire response is ready.
The API also allows setting parameters like temperature (for randomness), top_p, etc., though defaults are usually fine for most tasks (Opus 4 is quite deterministic by nature, given its coding specialization). When integrating, note that Claude’s responses include both the content and metadata.
The JSON response will have a structure like {"completion": "...text...", "stop_reason": "...", "model": "claude-opus-4-1-...","usage": {...}}. The stop_reason is important: if it’s max_tokens or error, it might mean the answer was cut off.
If it’s stop_sequence or end_turn, it ended naturally. Always handle these cases (e.g., if cut off, you might call again asking “continue from where you left off”).
Anthropic has also partnered with cloud providers – Claude models (including Opus 4) are offered on Amazon Bedrock and Google Cloud Vertex AI as managed services.
If you use those platforms, the integration might differ slightly (e.g., using AWS SDK or Google’s endpoints), but the core concepts (model ID, prompts, etc.) remain the same.
SDKs and CLI Tools: In addition to the Python SDK shown above (which is open-source on GitHub and installable via pip), Anthropic provides a command-line interface (CLI) tool called Claude CLI.
The Claude CLI allows you to chat with Claude directly from your terminal or integrate it into shell scripts. It’s especially handy for quick queries or piping output to other tools.
For instance, you can install it (via pip install anthropic which includes a CLI entry point) and run: claude chat --model claude-opus-4 to start an interactive session with the model in your console.
This is great for debugging prompts or just using Claude as a smarter terminal assistant. There are also community CLI wrappers (like one called “cla” on Reddit) that offer streamlined shell integration.
For agent-specific development, Anthropic released the Claude Agent SDK (also referred to as Claude Code SDK). This is a toolkit to build your own AI agents on top of Claude.
It includes libraries and patterns to manage tool use, function calling, conversation memory, etc., so you don’t have to implement those from scratch.
For example, the Agent SDK might allow you to declaratively define a set of tools and have a loop that feeds Claude’s outputs back in until a task is complete.
Anthropic’s engineering blog also provided best practices for using Claude Code in scripts and automation. If your goal is to create a custom agent (like a specialized Copilot for your company’s codebase), exploring the Agent SDK could accelerate that development.
Finally, standard tools like LangChain, LlamaIndex, and other LLM frameworks have connectors for Anthropic’s API. You can plug Claude Opus 4 into these frameworks to leverage their prompt orchestration capabilities.
For instance, LangChain’s Anthropic integration lets you use Claude as a drop-in ChatModel, so you can compose chains or agents using LangChain’s abstractions but with Claude’s intelligence powering them.
Embedding Claude into IDEs, Pipelines, and Dev Tools: Anthropic has made Claude Opus 4 accessible in developers’ daily workflows. A notable offering is Claude Code for IDEs: there are official extensions for VS Code and JetBrains IDEs that integrate Claude for coding tasks.
Once installed and authenticated, these extensions let you ask Claude questions about your code, generate code in the editor, or have Claude review diffs.
For example, in VS Code you might select a function and ask “Optimize this function for readability,” and Claude will suggest an edit, which you can apply directly. The integration is fairly seamless – Claude’s suggestions appear as inline diff hunks or as comments.
Because Claude can run in the background (even via GitHub Actions), you can also set up CI pipelines that use Claude. Imagine a pull request workflow where Claude automatically adds a comment summarizing the PR or pointing out potential bugs.
In fact, Anthropic previewed Claude Code on GitHub where you tag the bot on a PR and it will analyze feedback or CI errors and suggest fixes. These kinds of integrations turn Claude into a co-developer in your version control system.
For data pipelines or devops pipelines, you can call the Claude API from any step where AI assistance is useful. This could be a step in a Jenkins pipeline that, say, generates a report of test results or refines documentation.
Or a Kubernetes operator that queries Claude for anomaly explanations when metrics spike. One pattern is using Claude for validation or generation tasks in a pipeline – e.g., after building documentation from source, have Claude proofread it for clarity or generate a summary.
Another pattern is ChatOps: integrating Claude with chat platforms (Slack, Teams) so developers or SREs can query it about system status or get help with commands.
Since Claude can output formatted text, it can even craft messages with markdown to post back to Slack with charts or tables of data if you wire it up.
When embedding Claude into products or user-facing tools, treat it similarly to how you’d embed any AI model: ensure you handle errors from the API, put safeguards if the content could be user-facing (even though Claude is safe, you might add your own filters for your domain), and monitor usage to optimize costs.
Speaking of which, cost management is an aspect of integration: Opus 4, being premium, is priced at $15 per million input tokens and $75 per million output tokens. If your integration is heavy-duty (lots of tokens), consider using Anthropic’s prompt caching or batch features in production to lower costs.
For example, you can batch multiple questions into one API call if they are non-urgent to amortize the overhead, or reuse a cached prompt for repeated runs to not pay twice. These considerations tie into deployment best practices, which we’ll discuss next.
Error Handling and Debugging
Even with a powerful model like Claude Opus 4, developers will encounter cases where the output isn’t as expected or things go wrong. This section covers common limitations and how to troubleshoot them, as well as dealing with rate limits and latency issues.
Common Limitations: Despite its advanced capabilities, Claude 4 still has the inherent limitations of large language models. One such limitation is hallucination – the model may sometimes produce incorrect information or make up an answer that sounds plausible but is not true.
Anthropic’s safety training reduces egregious cases of this, but it does not eliminate the LLM tendency to “confidently improvise” when unsure. For example, Claude might fabricate the name of a non-existent library function if asked something it doesn’t know.
To mitigate this, whenever possible, ask Claude to show its reasoning or double-check work. You can prompt it: “If you are not sure, say you don’t know.” In many cases Claude will follow that and avoid a direct hallucination.
Another limitation is with highly technical or math problems: Claude is very good, but on certain math or logic puzzles, it might lag behind specialized models.
As IntuitionLabs analysis noted, Claude’s score on a challenging math competition (AIME) was about 75.5% whereas an OpenAI model reached ~89%. So for tasks like complex calculus or competitive programming puzzles, Claude might not always get the optimal solution on the first try.
A workaround is to have it generate multiple attempts or reason step-by-step (you can literally prompt “solve step by step” and check its logic). Similarly, while Claude is multimodal in understanding images, if you use that feature via the API, know that extremely detailed image analysis might be better handled by specialized vision models in some cases.
Claude’s safety filters can also be a source of apparent limitation. Sometimes, the model might refuse a request or return a safe-completion even if the request was not truly harmful – it could be a false positive triggered by wording.
If you get a response like, “I’m sorry, I can’t help with that,” and you believe the request was reasonable, you may need to rephrase the prompt or clarify your intent.
For example, including a legitimate use case: “This is for a penetration test in a safe environment” might convince it to output code for an exploit, whereas without that context it might refuse.
Always keep the usage policy in mind: Claude won’t produce disallowed content (self-harm advice, explicit illegal instructions, etc.), and as a developer you shouldn’t try to force it – aside from ethical reasons, the model is programmed to resist those.
Troubleshooting Poor Completions: If Claude’s output is off the mark (irrelevant, incorrect, or low quality), there are several strategies to debug and improve the results:
- Refine the prompt: Re-examine how you asked the question. Often a poor completion is due to an ambiguous or under-specified prompt. Adding more detail or constraints can dramatically improve accuracy. If the answer was incorrect, include the correct info in the prompt and ask it to use that. For instance, “Actually, the previous answer is wrong because ___. Please try again with that in mind.” Claude will take that feedback and usually correct itself.
- Use step-by-step mode: Encourage Claude to reason or outline before answering. You can prompt it like: “Think step by step about this. First, enumerate the things you need to consider, then answer.” Claude might then produce a chain-of-thought (especially if you use the
extended_thinkingmode via API), which you can inspect. If the reasoning seems to veer off course at a certain step, you can intervene by providing a correction for that step and asking it to continue. This interactive debugging is quite effective – it’s like watching how the model “thinks” and nudging it when it goes wrong. - Adjust model settings: If outputs are too random or verbose, check the generation parameters. A high
temperature(>1) can cause more creativity (and potential nonsense), so for deterministic tasks like coding, a low temperature (0 to 0.5) is better. Conversely, if the model seems too rigid or refuses to think outside the box, a slightly higher temperature or adding some randomness (e.g. nucleus sampling withtop_p) might help. Also, if the completion stops mid-sentence (maybe the model thought it hit a stop token or max length), increasingmax_tokensor removing a stop sequence can fix that. - Extended vs Instant mode: Claude’s hybrid reasoning means sometimes it might not “think long enough” if it decides to answer instantly. If you find the solution requires more analysis, you can force or encourage extended mode. The API allows a parameter for “thinking time” or budgets (Anthropic calls it “thinking tokens”). By granting the model a larger thinking budget, you essentially allow it to internally iterate more. On the flip side, if Claude is over-thinking a simple query (which can happen rarely, resulting in an overly verbose answer), you might set a lower budget. These settings are more advanced and might be abstracted away if using default endpoints, but it’s good to know they exist.
- Few-shot examples: Provide examples of the kind of answer you expect. For instance, “Q: [some question]\nA: [desired style answer]\nQ: [your question]\nA:”. Claude will often mimic the style or approach from the example. This is particularly useful for formatting (like showing an example of a JSON output in the prompt will almost guarantee the next answer is JSON).
If none of these fix the issue, consider whether Claude’s knowledge cutoff (March 2025 for Claude 4) might be the cause – it won’t know specifics after that date unless provided via context or tools. In such cases, use the tool function (e.g. a web search) to fetch the needed info and feed it to Claude.
Handling Rate Limits and Latency: Claude Opus 4 is a large model, and with great power comes some throttling. If using the Claude API directly, you’ll have rate limits on requests.
While Anthropic doesn’t publicly disclose exact rate limits (and they can vary by account tier), you might encounter HTTP 429 errors if you send too many requests too quickly.
A best practice is to implement an exponential backoff – if a request is refused due to rate limit, wait a bit and retry. You can also contact Anthropic for higher limits if needed (enterprise customers often get higher caps).
Latency is another consideration. For short prompts, Claude is quite fast (often responding in a second or two). But if you’re utilizing that 200k context or generating a very long output (say tens of thousands of tokens), the completion can take tens of seconds or even a minute.
Anthropic’s service will keep the connection open – in fact on AWS Bedrock, the timeout for Claude 4 is 60 minutes for a single request, acknowledging it might work on something for an hour.
If you have a client library with a default timeout (e.g. some HTTP clients default to 30s or 60s), ensure you increase the timeout for long contexts. Otherwise, you’ll think Claude didn’t respond, when actually the client cut it off.
To mitigate latency, leverage streaming as mentioned (so the user sees tokens as they come). You can also design your system to do heavy tasks in an async/background job, especially if using extended thinking.
For example, in a web app, if a user asks for an in-depth code analysis, you might immediately acknowledge the request and then update with the answer when ready, rather than blocking HTTP for 45 seconds.
Another tip for latency and cost: use batch processing for non-real-time tasks. Anthropic offers a batch mode where you can send multiple prompts in one API call. The model processes them together and you get multiple outputs back, with a discount on token pricing.
This is useful if, say, every night you want to generate reports for 100 repositories – you could batch them in fewer calls. Just be mindful of not exceeding the context window when batching (each prompt+output still has to fit).
Finally, monitor the token usage in responses (response['usage']). If you see unexpectedly large token counts (maybe you accidentally sent the whole internet in the prompt!), that could be causing slowdowns.
Optimize your prompt to reduce waste. Use caching for repeated contexts as mentioned (Anthropic’s prompt caching can save both time and money by reusing earlier computation).
In summary, handle errors by analyzing and refining prompts, be mindful of the model’s knowledge limits and safe-completion behavior, and design your application to gracefully handle the slower, heavier nature of Claude Opus 4 when it’s pushed to its limits. With careful engineering, you can get reliable and fast performance for the majority of use cases.
Best Practices for Deployment
Deploying Claude Opus 4 in a production or team environment requires careful planning to get the most out of the model while maintaining efficiency and control. Here we outline best practices for using Claude in workflows, automating processes, and configuring the model for reliable production use.
Workflow Automation and Integration: One of the promises of Claude Opus 4 is workflow automation – using AI to handle routine or complex tasks end-to-end. To achieve this in production, identify the tasks in your development or business process that Claude can augment.
For instance, code review is a workflow where Claude can be inserted: when a developer opens a pull request, you can have a bot (powered by Claude) automatically add a review comment suggesting improvements or pointing out potential bugs.
Many teams also use Claude for knowledge management: whenever new technical documentation is added, Claude can summarize it and post in a Slack channel for the team. The key is to integrate Claude’s API calls into the automation scripts or pipelines you already have.
Use event-driven triggers (webhooks, CI pipeline steps, cron jobs) to decide when to invoke Claude, and ensure the outputs are routed to the right place (commit back to repo, send message, update database, etc.).
Keep human oversight in the loop, especially initially – for example, maybe the AI code review comments are tagged in a way that developers know they came from Claude, and they can choose to accept or ignore them.
Over time, as confidence grows, you might let Claude auto-approve very simple changes (some teams have done this for minor documentation fixes, etc., where the risk is low).
Using Claude with DevOps and Data Pipelines: In DevOps scenarios, Claude can be used to automate analyses of logs, configuration adjustments, and even incident response drafting. Best practice here is to treat Claude as a suggestions engine rather than an autonomous actor (unless you’re very confident).
For example, if a monitoring alert fires at 3 AM, you could have Claude instantly generate a hypothesis and step-by-step remediation plan for the on-call engineer. This doesn’t mean it executes changes on the servers, but it provides a starting point that can save precious time.
In data pipelines, Claude can transform data or interpret results. Suppose you have a daily pipeline that produces a CSV of key metrics – you can add a step where Claude reads that CSV (converted to text) and produces a summary in natural language for an executive report.
One clever practice is to use Claude to validate outputs of pipelines. If you have a machine learning model that classifies something, you could occasionally ask Claude to assess some outputs for consistency or errors (because Claude has both reasoning and some domain knowledge). It’s like an AI-on-AI check.
For both devops and data uses, ensure you have fallbacks. If Claude fails (due to API downtime or an unexpected prompt issue), your pipeline should handle that gracefully – maybe by using a simpler logic or leaving a section blank with a note.
Since Anthropic’s service is quite stable but not immune to hiccups, designing idempotent jobs (that can retry an AI call) and caching results is prudent.
Model Configuration for Production: When moving to production, you’ll want to lock down certain model settings and behaviors. Here are some recommendations:
- Versioning: Use explicit model IDs (with date/version) rather than a vague “latest” alias. This ensures reproducibility. For example, stick to
claude-opus-4-1-20250805if that’s the version you tested and validated. Anthropic will release new versions (Opus 4.2, 4.5, etc.), but you can opt-in to those when you’re ready. This prevents sudden changes in behavior from breaking your app. - Temperature and Determinism: In many production scenarios (especially coding), you want deterministic outputs. Set temperature to 0 (or near 0) to reduce randomness. This way the model’s output is repeatable given the same prompt. If you do need multiple creative options (like generating several code implementations to choose from), you can use the
nparameter or call the API multiple times with a higher temperature in a non-prod environment, then pick one to use in prod. - Max Tokens and Budgeting: Configure
max_tokens_to_samplein the API to a sensible limit for your use case, to avoid runaway costs or excessively long outputs. For example, if you never expect more than 1000 tokens of answer, set that as a hard cap. Also, monitor how many tokens your prompts are using. If you see prompts creeping up in size (maybe you keep adding instructions), consider cleaning them up or using the prompt caching feature. Anthropic’s pricing page highlights that prompt caching can save up to 90% costs on repeated content, which is huge in production. Implement caching for any static or slow-changing prompt parts. - Prompt Management: Treat your prompts as code – keep them versioned (maybe in a config or even code comments), especially system prompts or few-shot examples. If something changes in the model or if you switch to Sonnet for cost on some requests, you’ll want to ensure prompts are tuned for each. It may be useful to maintain a test suite for your prompts: a set of sample inputs and verifying the outputs meet certain criteria. This is like unit tests for your AI behavior.
- Safety and Moderation: Although Claude has in-built safety, if your domain has specific compliance needs (e.g., financial or medical), add your own layer of checks. For instance, you might run Claude’s output through a regex filter to ensure no PII is being accidentally revealed (if you provided some in context). Or if using it to answer questions for users, you might want to double-check any factual claims it makes by cross-verifying with a knowledge base.
- Monitoring and Feedback: In production, continuously monitor the performance of Claude’s outputs. This can be through user feedback loops (have a thumbs-up/down for answers if user-facing), or internal logging of problematic cases which you later review. Anthropic improves models periodically; if you find systematic issues, report them – but also you can often address them by prompt tweaks on your side. Logging is important: record prompt inputs and model outputs (with careful handling of sensitive data) so you can trace what went wrong if there’s a bug or complaint. This also helps in debugging, as sometimes a prompt that worked fine 100 times behaves oddly on the 101st due to an edge case input.
- Cost Management: We touched on caching and batching for cost. In addition, consider using the right model for the job. Claude Opus 4 is amazing but expensive. If you have a mix of tasks, you could route simpler or less critical ones to Claude Sonnet 4 (which is cheaper). Sonnet 4 shares the 200k context and has good performance, just slightly less “frontier” than Opus. Using a tiered approach (Opus for the hardest tasks, Sonnet for standard tasks, maybe Claude Instant or smaller for trivial ones) can optimize expenses. Anthropic’s pricing and packaging allow using multiple models under the same account. For instance, you might use Opus for coding assistance but use Sonnet for a documentation chatbot where absolute top reasoning isn’t required. This strategy ensures you get the best ROI from the AI.
Deploying an AI like Claude Opus 4 is as much about engineering discipline as deploying any other critical service. By following these best practices – automating wisely, configuring the model parameters, monitoring actively, and controlling costs – you can harness Claude 4’s capabilities to significantly boost productivity and outcomes in your software projects without unpleasant surprises.
Conclusion
Claude Opus 4 represents a significant advancement in AI capabilities for software development and beyond. For developers and engineers, it can serve as a tireless coding assistant, an intelligent devops analyst, and an autonomous agent that tackles complex projects start-to-finish.
By integrating Claude Opus 4 into development workflows, teams have reported substantial productivity gains, such as faster completion of tasks and reduction in manual effort by large percentages.
Routine tasks like code generation and documentation can be automated, while more complex endeavors like multi-module refactoring or extensive data analysis become feasible in a fraction of the time they would normally take.
Strategically, adopting Claude Opus 4 can give organizations an edge in AI-enhanced development. It enables a higher level of abstraction – developers can focus more on problem definition and high-level design while the AI handles the boilerplate and grunt work.
This can accelerate development cycles and even unlock projects that were too resource-intensive before (e.g., reviewing an entire enterprise codebase for consistency, or doing exhaustive threat modeling).
Claude 4’s long context and reasoning mean it can ingest the full breadth of a problem (all your requirements, all your code, all your data) and provide holistic assistance, which was not possible with earlier limited-context models.
Of course, realizing these benefits requires careful prompt engineering, system design, and oversight. But as detailed in this guide, there are established techniques to make the most of Claude Opus 4 safely and efficiently.
Anthropic has positioned Claude Opus 4 as a “virtual collaborator” – and in many ways it lives up to that description. It can brainstorm with you, write and revise code as a partner, and even take the initiative in long tasks when given the green light.
In conclusion, Claude Opus 4 is a powerful new tool in the developer’s toolbox. Its combination of a massive context window, superior coding skills, multi-step reasoning, and integration hooks for tools allows developers to build solutions that blend human insight with AI horsepower.
Whether you’re using it to automate your infrastructure, build an AI coding assistant, or analyze data at scale, Claude Opus 4 can dramatically enhance productivity and outcomes.
By following the technical guide above, developers should be well-equipped to harness Claude Opus 4 effectively – transforming workflows and pushing the frontier of what’s possible in software engineering with AI. Welcome to the era of AI-enhanced development, and happy building with Claude Opus 4!