
Claude 3 Opus is Anthropic’s most powerful large language model in the Claude 3 series – effectively the “flagship” model built for maximum capability. It’s a massive Transformer-based AI model with a parameter count in the 100+ billion range.
Anthropic has fine-tuned Claude 3 Opus using their Constitutional AI approach (a technique similar to RLHF but guided by an explicit set of principles) to ensure the model’s outputs are helpful and aligned with ethical guidelines. This robust architecture and training translate into exceptional performance on complex intellectual tasks.
Claude 3 Opus’s core strengths lie in its depth of understanding and reasoning ability. It achieves near-human levels of comprehension and fluency on challenging prompts.
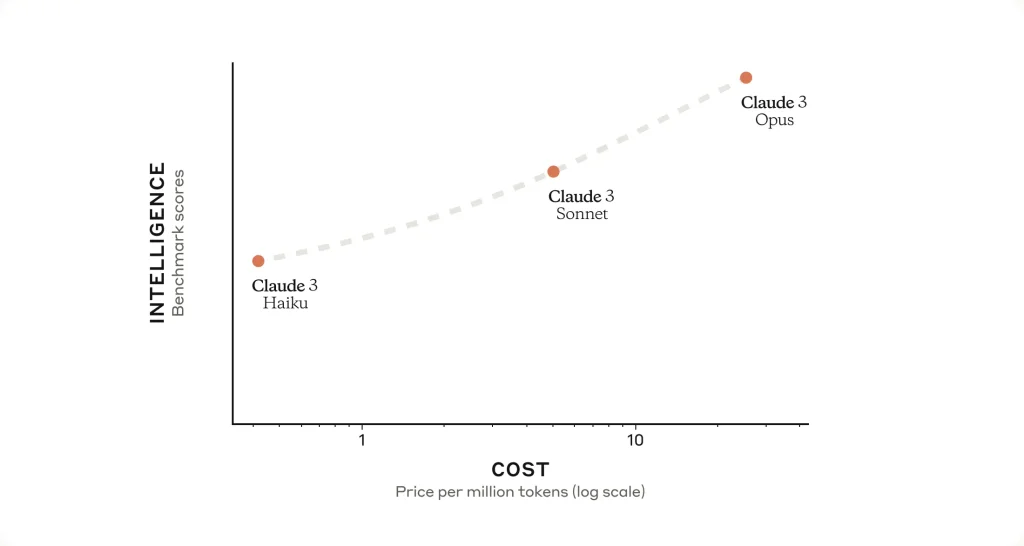
In fact, Opus outperforms most peers on rigorous academic and professional benchmarks – including expert knowledge tests (MMLU), graduate-level reasoning (GPQA), and math problems (GSM8K) – leading the frontier of general intelligence.
The model can navigate highly open-ended questions or “sight-unseen” scenarios with remarkable accuracy and coherence, making it well-suited for tasks that require broad knowledge and multi-step reasoning.
Another architectural strength of Claude 3 Opus is its alignment and reliability. Due to iterative fine-tuning and safety training, it is less likely to hallucinate facts or refuse harmless requests.
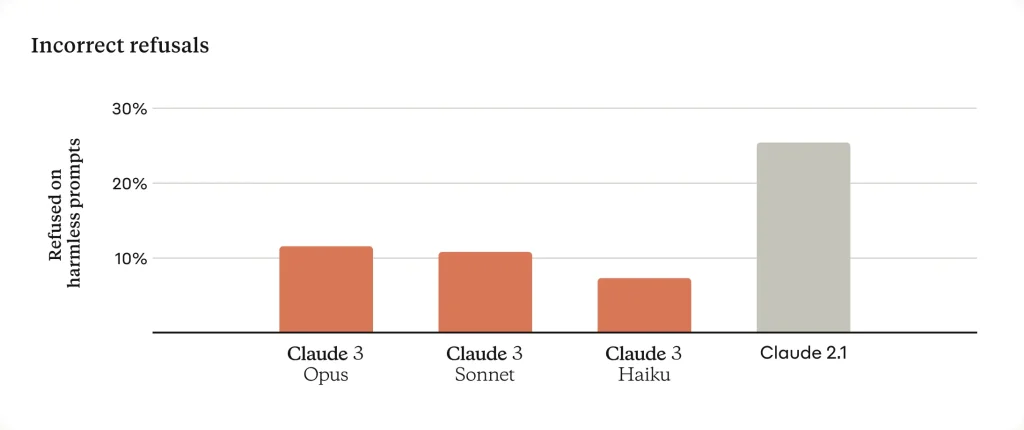
Anthropic reports that Opus produces roughly twice as many correct answers on tricky questions (with fewer incorrect or made-up answers) compared to the previous generation model.
It’s also significantly less prone to unnecessary refusals – the model demonstrates a nuanced understanding of queries and will only refuse when truly necessary (showing far fewer false refusals than earlier Claude models).
This means developers can expect trustworthy and relevant outputs from Claude 3 Opus, even on sensitive or complex queries, as long as those queries stay within ethical use guidelines.
Overall, the combination of a giant-scale Transformer architecture and careful alignment gives Claude 3 Opus an unparalleled mix of intelligence, accuracy, and safe behavior for advanced AI applications.
Token and Context Limits, I/O Format, and Long-Document Handling
One of the standout features of Claude 3 Opus is its very large context window. It supports input prompts up to 200,000 tokens in length (roughly 150k words), allowing developers to provide entire books, multi-chapter documents, or extensive codebases as input.
This 200K-token context window is game-changing – the model can effectively process huge documents or conversations without losing track of earlier details.
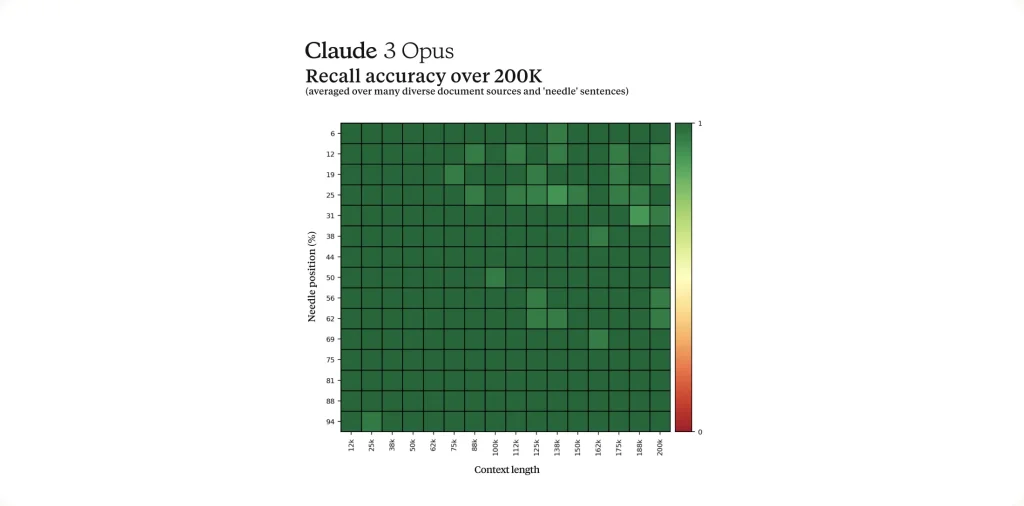
In fact, internal tests showed Claude 3 Opus achieving over 99% accuracy in recalling specific details from massive texts in “needle-in-a-haystack” evaluations.
For specialized needs, Anthropic has even enabled extended contexts beyond 1 million tokens (over 800k words) for select enterprise customers, demonstrating the model’s underlying capability to handle truly enormous inputs (though the 1M-token mode is a limited beta for now).
Handling long documents isn’t just about accepting large input — it’s also about retaining and utilizing that information effectively. Claude 3 Opus has been engineered for near-perfect long-term recall within a prompt.
It can accurately answer questions about or summarize information from deep within a lengthy input, even if that information appears hundreds of pages earlier in the context.
The practical benefit is that you can feed in extensive background material (such as multiple knowledge base articles, lengthy research papers, or a whole code repository) and the model can draw upon any part of it when formulating its response.
This long-context capability leads to more natural, coherent interactions over lengthy sessions: Claude can maintain awareness of earlier content without needing the developer to repeatedly re-provide context.
The model’s “memory” of the prompt is strong, enabling it to produce consistent long-form outputs (e.g. maintaining narrative consistency in a long essay) and perform tasks like cross-referencing or comparing sections of a large document.
Developers have noted that a large context window enables use cases like analyzing multi-document sets or holding extended dialogues where the model remembers all prior instructions and facts.
Input/Output format: To leverage Claude 3 Opus via API, developers provide input in a chat-style format. The Anthropic API uses a JSON message schema where you send a list of messages (e.g. system, user, assistant) in a single API call.
Each message has a role (such as "user" for your prompt, "assistant" for the model’s replies, and optionally a "system" role for instructions) and a content payload. For example, a JSON request might look like:
{
"model": "claude-3-opus-20240229",
"messages": [
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Explain the code in the attached file."}
],
"max_tokens": 2000,
"temperature": 0,
"stop_sequences": ["\n\nHuman:"]
}
In practice, the format allows inclusion of not just plain text but also other content types like images (as described in the next section). The model’s output is always text.
Claude 3 Opus can return very large completions – by default up to around 32,000 tokens of output in a single response (enough for dozens of pages of generated text). You can set a max_tokens parameter to limit the length of the response.
If streaming mode is used, the API will send back the completion incrementally, token by token, which is useful for long answers to keep latency reasonable.
Notably, Claude 3 Opus’s API has moved to this chat Messages API format (as opposed to a raw text completion endpoint) to support its advanced features. In fact, using the older completion-style API will not expose the full capabilities of Claude 3 (and is incompatible with image inputs).
Anthropic and its partners require using the new message-based format for Claude 3 models; for example, AWS’s Bedrock documentation emphasizes upgrading to the messages API for features like image processing.
In summary, developers interact with Claude 3 Opus by constructing a conversation (even if it’s a single-turn conversation) and sending that to the model, then reading the model’s reply from the API response.
When working with extremely large contexts, a few practical tips apply: it’s often wise to place the most critical information early in the prompt or highlight it, so the model can readily latch onto it.
Claude will read the entire input, but like any model, it gives somewhat more weight to recent context (and the prompt as a whole has a finite attention budget).
Organizing your prompt – e.g. by sectioning a long document, or providing a summary before the full text – can help ensure important details aren’t overlooked.
Fortunately, Claude 3 Opus’s attention mechanisms are very advanced, so it can handle straightforward long inputs without special tricks; but good prompt hygiene (structured, relevant inputs) will maximize accuracy on long documents.
Supported Modalities: Text, Code, and Image Understanding
Claude 3 Opus is a multimodal model – it accepts both textual and visual inputs – though it produces only text outputs. The primary input modality is of course text (natural language). This includes all forms of text: questions, instructions, as well as programming code or pseudo-code.
The model was trained on a vast corpus of natural language and coding data, so it can understand software-related prompts and generate code with high proficiency. Code is essentially treated as a form of text by the model, but with specialized knowledge of syntax and programming concepts.
One of Claude 3 Opus’s hallmarks is robust code handling: it can write code, debug code snippets, explain code, and even help refactor or improve existing code.
These coding capabilities are among its core strengths, making it comparable to dedicated code-generation models. Developers can input code (or error logs, etc.) and get back well-formatted code suggestions or analyses in return.
In addition, Claude 3 Opus and the Claude 3 family introduced substantial vision capabilities. The model can intake images as part of the prompt and analyze or describe them.
For example, you can provide a diagram, a chart, a photograph, or a screenshot embedded in your prompt, and Claude 3 Opus will interpret the visual content and incorporate that understanding into its answer.
Anthropic reports that the Claude 3 models can handle a wide range of visual formats – including photos of real-world scenes, scanned documents, charts/graphs, and even technical diagrams.
This is extremely useful for tasks like reading data off a chart image, understanding the content of a PDF (which may include images or graphics), or describing an uploaded picture. The model’s image comprehension is on par with other cutting-edge multimodal AI systems.
From the developer’s perspective, adding an image to the prompt is done by sending a special content object in the API request. In the JSON message, you include an item with "type": "image" and either a URL or a Base64-encoded image string as the source.
Claude 3 Opus will then process that image alongside the textual part of the prompt and generate a text answer. For instance, you might ask: “What does this chart indicate about our sales?” and attach an image of a sales graph; the model could reply with an analysis of the graph’s trends, in text form.
Keep in mind that image inputs count toward the token limit (the image is internally converted to a sequence of tokens when processed). Roughly, 1 million pixels of image ~ 1,334 tokens, so an 800×600 image might consume on the order of a few hundred tokens.
The API allows multiple images per request (up to 100 images in one call for enterprise API, within size limits), enabling comparative image analysis or multi-page PDF processing. This multimodal support opens up a host of use cases like document QA where the document contains graphics, UI automation by analyzing screenshots, and more.
In summary, Claude 3 Opus supports:
- Text – all natural language inputs and outputs, plus structured text (JSON, XML, markdown, etc.) and programming code as text.
- Code – understanding of code is a built-in capability (no special mode needed; you simply include code in the prompt or request code in the output). It can handle languages from Python and JavaScript to Java, C, or Bash, and can reason about algorithms or debug code. This makes it a powerful coding co-pilot out of the box.
- Images – input modality for vision tasks. You get textual descriptions or analysis in response. This is useful for image captioning, extracting data from charts, reading diagrams, or any scenario where visual understanding is required.
It’s important to note that Claude 3 Opus’s outputs are text-only – it does not generate images. When it “describes” an image, the description is returned in words.
Also, as of Claude 3, there’s no direct audio or speech modality in the model (you can pair it with external speech-to-text or text-to-speech if needed, but the model’s API itself only handles text and image inputs).
In general, the addition of image understanding in Claude 3 Opus means developers can build more holistic applications that combine text and visual data.
For example, an app could let a user ask a question about a PDF document by sending the PDF pages as images to Claude, and the model could answer questions referencing both the text and figures in that PDF.
Key Capabilities of Claude 3 Opus
Claude 3 Opus exhibits a broad range of capabilities that developers can harness. Here are some of its most notable strengths and skills:
- Advanced Reasoning and Problem Solving: Opus can handle complex logic puzzles, multi-step reasoning tasks, and abstract questions that require deduction. It approaches challenging problems with a step-by-step reasoning ability close to that of a human expert. In benchmarks, Claude 3 Opus has excelled at tasks like graduate-level QA and logical reasoning puzzles, reflecting its powerful chain-of-thought capabilities. For developers, this means you can trust Opus with tasks like analyzing the cause-and-effect in a scenario, performing root-cause analysis from data, or figuring out nuanced solutions in domains like finance or medicine (within the model’s knowledge scope).
- Natural Language Understanding and Generation: The model has an excellent grasp of language, enabling it to interpret complicated instructions or texts and generate coherent, contextually appropriate responses. It’s fluent not just in English but in multiple languages – Anthropic specifically improved Claude 3’s performance in non-English languages such as Spanish, Japanese, and French. Claude 3 Opus can thus be used for translation, multilingual chatbots, or analysis of foreign-language documents. Its generated language is typically clear and well-structured. It can adapt tone and style as needed – from formal technical writing to a casual conversational style – often with just minimal prompting. Because of the alignment training, Opus also tries to stay factual and truthful; if it doesn’t know something or the answer is uncertain, it’s more likely to state that it’s unsure, rather than fabricate an answer. This makes it a reliable language assistant for tasks like summarizing articles, answering questions, drafting content, and more.
- Coding and Software Development Assistance: Coding is a top-tier skill of Claude 3 Opus. The model can write code, explain code, debug code, and generate pseudo-code or algorithms on demand. It was evaluated on coding benchmarks (like HumanEval) and performs at an industry-leading level. For example, you can ask Opus to generate a Python script to accomplish a certain task – it will output well-commented code that often runs correctly on the first try. It can also help with code review: if you provide a code snippet and ask for potential bugs or improvements, it can point them out. Thanks to the 200K context, you might even feed multiple source files or an entire function library and have Claude analyze how they work together. This is extremely useful for developers working on large projects. Additionally, Opus can produce explanations of code for documentation or learning purposes (e.g., “Explain what this function does”). It supports a wide range of programming languages and can even generate things like HTML/CSS or SQL queries. When it comes to debugging, the model can follow error messages or stack traces and suggest likely fixes. All these abilities make Claude 3 Opus an excellent AI pair-programmer or code assistant.
- Document Analysis and Synthesis: Claude 3 Opus is adept at tasks involving long documents or multiple documents. It can summarize long texts, extract specific information, compare and contrast documents, or answer detailed questions about a document’s content. For instance, a developer can feed in a lengthy financial report or a legal contract and ask Opus to pull out key points or answer questions – the model will comb through the entire text to generate an answer. Thanks to near-perfect recall in long contexts, it won’t miss relevant details that appear deep into the text. It’s also capable of understanding structured documents (like JSON or CSV data embedded in text, or tables in a document) and can reason about the data. Some example capabilities: summarizing an academic paper while preserving all the important findings, analyzing a log file to identify patterns, or reading a software API documentation to answer questions about how to use a function. Multi-document QA is another strength – you could provide several related documents (within the token limit) and ask questions that require synthesizing information across them, and Claude will integrate the info in its response. This capability is hugely valuable for enterprise search, research assistants, or any use case where large volumes of text need to be distilled and understood.
- Content Creation and Creative Tasks: Claude 3 Opus can generate high-quality content given appropriate prompts. This spans a variety of creative or generative tasks: writing articles or blog posts, composing emails, creating marketing copy, drafting press releases, and so on. It excels at maintaining a requested tone or style – you can ask for “an enthusiastic tone” or “professional legal tone”, etc., and it will adjust accordingly. The model can also engage in brainstorming and idea generation, producing creative suggestions on open-ended topics. For example, it can help come up with campaign ideas, product names, or plot outlines for a story. While we are focusing on developer-oriented use, these generative capabilities mean you can integrate Claude 3 Opus into applications that require content generation or transformation (e.g., rewriting text in a different style, summarizing user input, generating chatbot replies, etc.). Notably, Opus’s large knowledge base and context window allow it to produce long-form content that remains coherent – such as multi-paragraph answers or multi-step plans – without losing the thread. It was designed to handle nuanced instructions, which means it can follow complex formatting requirements (like “output the result as a JSON object” or “produce a markdown table of these facts”) reliably as well.
- High Precision and Accuracy: Underlying all the above capabilities is Claude 3 Opus’s emphasis on accuracy. The model was trained and evaluated to minimize hallucinations and incorrect statements. It tends to cite facts it’s confident in and avoid making up information. Anthropic has indicated that Opus significantly reduces the rate of false or hallucinated answers compared to prior versions. Moreover, Claude 3’s upcoming support for citation (pointing to source material for its answers) was hinted, which may further improve trust in its outputs. While citations may not be fully available in Claude 3 Opus at this moment, the model’s responses are already more evidence-based and often come with caveats or uncertainty acknowledgments if the query is beyond its knowledge cutoff. For developers, this means when building user-facing applications, Claude 3 Opus is less likely to confidently state wrong facts, and more likely to either give a correct answer or gracefully indicate it’s unsure – a critical quality for enterprise and professional use.
In sum, Claude 3 Opus is a general-purpose AI assistant with special prowess in coding, deep reasoning, language tasks, and handling very large or complex inputs.
It’s this combination of capabilities that makes it unique – where some models might be good at code but not at reading long documents, or vice-versa, Opus aims to do it all at a high level of performance.
This makes it a compelling choice for developers who need a single model to power a variety of features in their applications.
Integration Methods via API and Platforms
Developers can access Claude 3 Opus through multiple integration channels, depending on the use case and platform preference. Below are the main methods to use Claude 3 Opus:
Anthropic API and Console: Anthropic provides a direct cloud API for Claude models. After signing up on the Anthropic developer platform, you obtain an API key which is used to authenticate requests.
To call Claude 3 Opus via the API, you send a POST request to Anthropic’s endpoint (e.g. https://api.anthropic.com/v1/messages) with your API key in the header and the conversation payload in JSON format.
The request must specify the model ID or alias for Claude 3 Opus (for example, claude-3-opus-20240229 or the latest alias). Using the API gives fine-grained control: you can set parameters like max_tokens, temperature, stop_sequences, etc., as shown in the earlier JSON example.
Anthropic’s API supports both synchronous completions and streaming. For initial exploration or non-programmatic use, Anthropic also offers a web console (the Claude Console/Workbench at console.anthropic.com and the Claude.ai chat interface).
In the Console Workbench, you can select Claude 3 Opus from a drop-down and interact with it in a chat UI – including uploading images if needed. This is great for testing prompts and seeing how the model responds before writing code.
The console also provides logging of usage and some debugging info. Overall, using the Claude API directly is ideal when you want to integrate the model into your own app backend or service; it requires managing API keys and abiding by rate limits (discussed below).
The Anthropic API is RESTful and requires no infrastructure on your part – the model is hosted by Anthropic and you just send requests to it and get responses.
Official SDKs (Python, JavaScript, etc.): To simplify integration, Anthropic offers official SDK libraries. For example, the Anthropic Python SDK (anthropic Python package) provides a convenient interface to call Claude models without manually constructing HTTP requests. Using the SDK, you can do something like:
import anthropic
client = anthropic.Anthropic(api_key="YOUR_API_KEY")
response = client.messages.create(
model="claude-3-opus-20240229",
system="You are a seasoned data scientist assistant.",
messages=[ {"role": "user", "content": "Analyze the dataset for trends."} ],
max_tokens=1000
)
print(response.content)This would handle building the request and returning the assistant’s reply directly. Similar SDKs or API client libraries exist for other languages (JavaScript/TypeScript, etc.). These libraries often also help with tasks like streaming the response or batching requests.
If you are in a setting like Jupyter or a script, using the SDK can speed up development. Under the hood, they still call the same Anthropic API endpoints.
Amazon Bedrock: Claude 3 Opus is available as a managed model through AWS Bedrock, Amazon’s AI service. If you are building on AWS or want to integrate Claude into an AWS-based application, Bedrock provides a convenient pathway.
With Bedrock, you don’t need an Anthropic API key; instead, you use your AWS credentials and Bedrock handles the Anthropic model behind the scenes. First, you would enable Claude 3 Opus on Bedrock (it may require requesting access in the AWS console, since it’s a third-party model).
Once enabled, you can invoke Claude via AWS’s SDK/CLI by specifying the model ARN or ID. For example, using the AWS CLI:
aws bedrock-runtime invoke-model \
--model-id anthropic.claude-3-opus-20240229-v1:0 \
--body '{"messages":[{"role":"user","content":[{"type":"text","text":"<your prompt>"}]}]}' \
--region us-west-2 > response.jsonThis CLI call (as shown in AWS’s documentation) sends a user message to Claude 3 Opus and writes the completion to a file. In code, you would use AWS SDK (e.g. Boto3 for Python or the AWS JS SDK) to call the Bedrock InvokeModel API similarly.
Bedrock offers a nice web Playground as well: you can go to the Bedrock console, choose Claude 3 Opus, and interact with it via a chat UI or try preset examples (like analyzing a quarterly report or generating code).
A key benefit of Bedrock is that it integrates with other AWS services and handles scaling – you don’t worry about hitting Anthropic’s service directly or managing keys (though Bedrock has its own usage quotas and costs).
Bedrock also ensures data doesn’t leave AWS (aside from being processed by the model provider), which might appeal for compliance.
In terms of features, Claude on Bedrock supports the same text and image inputs (the Bedrock API has adopted the Anthropic message format including the ability to send image content). So you can perform multimodal prompts on Bedrock as well by including image blocks in the JSON.
When using Claude 3 Opus via Bedrock, you’ll be subject to AWS’s pricing for that model (which roughly aligns with Anthropic’s pricing plus any AWS overhead) and AWS’s terms of use. It’s a good option if you’re already in the AWS ecosystem or want a fully managed solution.
Google Cloud Vertex AI: Claude 3 Opus is also offered through Google Vertex AI’s Model Garden as a third-party model. Google has integrated Claude models into Vertex AI, allowing GCP customers to use them in a serverless, scalable manner.
To use Claude 3 Opus on Vertex, you need to enable the Generative AI API in your GCP project and have access to the Claude model (Google may require acknowledging terms for third-party models).
Once set up, you can call the Vertex AI API with the specific model name (for example, projects/your-project/locations/us-central1/models/claude-opus-3 – the exact naming might differ as versions update).
The request format on Vertex is slightly different but conceptually you send a prompt and get a completion.
Vertex AI supports features like streaming responses (via server-sent events), and you can use Vertex’s client libraries to call the model.
One advantage of Vertex AI is that it offers enterprise security and compliance out-of-the-box – Google ensures that using Claude via Vertex meets FedRAMP High and other security standards, which can be important for government or healthcare projects.
Vertex AI also provides tooling like the Prompt Playground and the ability to evaluate or monitor requests in the GCP console. In terms of cost, it’s pay-as-you-go by default: you pay for the usage (tokens) similarly to how you would on Anthropic’s API.
Google also offers a “provisioned throughput” option, where you can pay a fixed rate to reserve a certain throughput for consistent high-volume usage. This can be useful if you have a very large-scale application and want to ensure Claude’s capacity with predictable pricing.
Overall, integrating via Vertex AI is ideal for developers already on Google Cloud or those who require the additional services Vertex provides (like data logging, monitoring, or using Claude in combination with other GCP ML pipelines).
Other Platforms and Integrations: Beyond the above, Claude 3 Opus might be accessible through other partner platforms or tools. For instance, there are community integrations (like Slack’s workflow or Notion AI) where Claude models power certain features.
Also, some AI startups (such as Relevance AI, which provided a Claude integration guide) offer Claude-powered services. While these aren’t “official” integration methods, it’s worth noting that Anthropic’s ecosystem is growing.
Most third-party integrations ultimately use the Anthropic API under the hood, so as a developer, the direct methods listed above give you the most control and up-to-date access to Claude 3 Opus.
In summary, developers have flexibility in how to deploy Claude 3 Opus. If you want low-level control and direct access, use Anthropic’s API (with your API key). If you prefer a managed solution or are working within AWS or GCP, Bedrock and Vertex AI provide first-class integrations.
Regardless of the method, the functionality of Claude 3 Opus remains the same, though each platform may have slight differences in request format or available tooling.
It’s also possible to start with one method (e.g., prototyping in the Anthropic Console or Vertex Playground) and then move to another for production (e.g., calling the API directly for a custom app) – the skills you learn in prompting and handling responses will translate across these platforms.
Authentication, Pricing, Rate Limits, and Performance Considerations
When using Claude 3 Opus, especially in production, developers must consider authentication, costs, and usage limits to ensure a smooth deployment.
Authentication & Access Control: If you’re using the Anthropic API, authentication is done via an API key. You include an HTTP header x-api-key: <YOUR_KEY> with each request to the Claude endpoint. API keys are obtained from Anthropic’s developer dashboard and tied to your organization.
It’s important to keep this key secure (do not embed it in client-side code). On Anthropic’s console, you can manage keys and monitor usage. For Amazon Bedrock, authentication is handled through your AWS credentials (IAM roles, user access keys, etc.) – you won’t deal with an Anthropic key directly.
Instead, you must have permission to use the Bedrock service and specifically the Claude model. Similarly, on Google Vertex AI, your GCP project and credentials manage access; you need the Vertex AI API enabled and the proper OAuth scopes or service account permissions to call the model.
In all cases, ensure that only authorized parts of your system can call Claude 3 Opus, as usage incurs costs and any misuse could lead to unexpected charges or data exposure. For interactive platforms (like claude.ai or the console), authentication is simply your login to Anthropic’s site.
Pricing: Claude 3 Opus is a premium model, and its pricing reflects the greater computational resources it uses. Anthropic charges based on the number of tokens processed: input tokens (the prompt you send, including any system instructions and image tokens) and output tokens (the text the model generates).
As of late 2024/early 2025, the base price for Claude Opus on Anthropic’s API is about $15.00 per million input tokens and $75.00 per million output tokens. In practical terms, 1,000 tokens of input costs about $0.015, and 1,000 tokens of output costs about $0.075.
These rates are substantially higher than for smaller Claude models (which might be $1–3 per million), so Opus is an investment for tasks that truly need its capabilities.
Third-party platforms generally use similar pricing models: for example, Google Vertex AI’s pricing page for Claude models will show roughly the same order of magnitude costs per token (with slight differences if they add service fees), and AWS Bedrock likewise bills per token for Claude usage.
It’s important to note that image inputs are also billed via token conversion – when you send an image, it gets encoded as tokens. For instance, a 1 megapixel image (~1000×1000 px) is roughly 1,334 tokens, which would cost on the order of $0.004 for input processing.
A very large image (or many images) can increase the prompt token count significantly. Always consult Anthropic’s official pricing page for the most up-to-date rates, as prices may change or discounts may apply for bulk usage.
In addition to base prices, Anthropic offers features that can influence costs. One is prompt caching: if you repeatedly send the same or similar prompts (like a system message or a long document that doesn’t change), Anthropic’s API can detect and cache those tokens, charging a lower rate (~10% of normal cost for cached tokens).
This can dramatically reduce cost for applications that use a fixed context across many queries. Another consideration is long-context pricing. If you utilize contexts beyond 200k tokens (in the future, as the 1M token context becomes available), Anthropic may have a special pricing multiplier for those very large prompts.
For example, enabling the 1M-token beta might incur higher per-token fees for the portion of the prompt beyond 200k. This is to account for the increased computational load of such huge contexts.
Rate Limits: To maintain service stability, Anthropic imposes rate limits on API usage. Rate limits are typically defined per organization (or per API key) and vary by the usage tier you’re in. At the default Tier-1 (entry level), the limits for Claude 3 Opus are around 50 requests per minute, 20,000 input tokens per minute, and 4,000 output tokens per minute.
This means in any rolling 60-second window, you can’t exceed 50 calls or send more than 20k tokens of prompt data (and likewise, the model won’t generate more than 4k tokens for you per minute on average).
These limits are sufficient for low to moderate use. If your needs grow, Anthropic automatically bumps you to higher tiers as you spend more (Tier-2, Tier-3, etc., each with higher allowances). For example, higher tiers might allow hundreds of thousands of tokens per minute.
There are also “acceleration limits,” which prevent a sudden spike from zero to very high usage – Anthropic recommends gradually increasing load to avoid 429 “Too Many Requests” errors. If you hit a rate limit, the API will return an HTTP 429 error along with a retry-after header to tell you when you can try again.
On third-party platforms, there are analogous limits: AWS Bedrock might limit TPS (transactions per second) or payload sizes based on your AWS service limits, and Vertex AI has its own quotas (e.g., QPS per project, and tokens per minute per model).
These can often be raised by contacting support if needed. Always design your integration to handle potential throttling – e.g., implement exponential backoff on 429 errors or queue requests if you approach the limit.
One useful strategy to maximize throughput under token rate limits is using the prompt caching feature mentioned earlier. Since Anthropic does not count cached tokens towards the input TPS limit for most models, if you have a large static context (like a long document you query repeatedly), enabling caching can let you reuse those tokens without hitting the limit as quickly.
As an example, with a 2,000,000 token/minute input limit and an 80% cache hit rate, you could effectively process 10 million tokens per minute because the 8 million cached tokens wouldn’t count against the limit. This is an advanced optimization – it requires you to send prompts in a way that caching can identify reuse (Anthropic’s docs detail this).
Performance Trade-offs: Due to its size and complexity, Claude 3 Opus is computationally heavier than smaller models, which has a few implications:
- Latency: Expect response times to be a bit slower with Opus, especially on large prompts. In Anthropic’s own comparison, Claude Opus’s speed is categorized as “moderate” latency, whereas lighter models can be “fast” or “instant”. Roughly, if a smaller model might respond in under 1 second for a short prompt, Opus might take a couple of seconds for the same – and for very long inputs/outputs, it could take tens of seconds to a minute to generate the full answer. This is generally still comparable to models like GPT-4 in speed. But developers building real-time applications (like a live chat) should be mindful of prompt sizes and perhaps implement streaming so the user can start seeing the answer as it’s generated. High latency can also sometimes be mitigated by requesting fewer tokens (limiting the answer length) or disabling any features that add overhead (for example, extremely large image inputs that need resizing will add processing time).
- Cost vs. Benefit: Because Opus is expensive, it’s not cost-effective to use it for trivial tasks. Developers should consider when to use Claude 3 Opus. For simpler queries or high-volume trivial questions, a smaller model (or even Claude Instant, if it were still available) could save a lot of cost. Claude 3 Opus truly shines when the task is complex, large-scale, or requires top-notch reasoning/accuracy. In other words, there is a trade-off between intelligence and speed/cost. Many teams find a hybrid approach useful: use Claude Opus for the hard cases and a cheaper model for easy cases, routing dynamically. Since this guide focuses on Opus exclusively, suffice to say that within the Claude 3 family, Opus offers the maximum capabilities but at the highest price and a somewhat lower throughput. Make sure this aligns with your project’s needs – e.g., for an application that must analyze a 300-page document in one go, Opus is likely the only choice; but for an interactive chatbot that needs lightning-fast responses to common questions, Opus might be overkill in production.
- Scaling Considerations: If you plan to scale your usage to many requests per second, you’ll need to manage the rate limits and possibly talk to Anthropic about higher tiers or enterprise plans. Also, keep an eye on concurrent usage – if you send many large requests in parallel, the responses might queue up server-side, affecting latency. Anthropic’s service is robust, but at extreme scales you might observe some throughput bottlenecks unless you have made special arrangements (like priority access). Both Bedrock and Vertex offer options like throughput reservations (on Vertex) or AWS’s general scalability to handle volume, but they come with increased costs. Always load test within your quota to see how latency behaves under load.
In summary, Claude 3 Opus for developers entails balancing its unparalleled capabilities with practical considerations of cost and performance.
Authenticate properly, budget for token usage (maybe set up monitoring and alerts for cost), respect rate limits or request increases for production, and design your system to use Opus where it adds the most value. By doing so, you can harness the full power of Claude 3 Opus without unwelcome surprises in latency or billing.
Best Practices for Prompt Engineering and System Design
Getting the most out of Claude 3 Opus requires not just plugging it in, but also crafting your prompts and context thoughtfully. Here are some developer best practices for prompt engineering, context design, and controlling the system’s behavior:
Be Clear, Specific, and Structured in Prompts:
Claude 3 Opus responds best to prompts that explicitly lay out the task and desired format. Vague prompts can lead to overly general answers. It often helps to structure your prompt into parts – for example: (1) a brief statement of context or what you’re trying to do, (2) a clear instruction of the task, and (3) any format requirements for the output. Anthropic’s experts suggest a template like: “Briefly describe your situation. State what you want to achieve. Specify how you want the response structured.” – this ensures the model knows the scenario, the goal, and the expected answer format. For instance, instead of asking: “Give me insights from this data,” you might say: “You are a data analyst. We have sales data from Q1 (attached). Goal: Identify any significant trends or anomalies. Format: Provide 3 bullet-point insights with a short explanation each.” By being precise, you reduce guesswork for the model and get more relevant results. Also, if you expect a certain style (e.g. terse bullet points vs. an essay), mention that explicitly in the prompt.
Use the System Message to Guide Behavior and Role:
Claude 3 Opus allows a system-level prompt which sets the context or persona of the AI assistant. Leverage this! Giving Claude a role can dramatically improve its performance for specialized tasks. For example, a system prompt like “You are an expert financial advisor with knowledge of stock markets and investment strategies.” will nudge the model to respond in the tone and with the knowledge of such an expert. Role prompting can yield enhanced accuracy and a tailored tone that matches the domain. When using system prompts, keep them concise but impactful – define the role or rules, but avoid overloading with too many instructions (which could dilute focus). Use the system message for high-level guidance (persona, style, what not to do) and put the concrete question or task in the user message. This separation helps the model maintain the role consistently. For instance, system: “You are Claude, an AI lawyer that explains legal documents in plain English.”; user: “(text of a contract)… Please explain the obligations of each party in this contract.” Now Claude will frame its answer as that helpful AI lawyer. Tip: You can also include global constraints in the system prompt, like “Always answer in a polite and factual manner. If you don’t know the answer, say so.” – Claude will generally follow such meta-instructions diligently.
Provide Examples (Few-Shot Prompting) for Clarity:
If your task is complex or has a specific format, consider giving one or two examples in the prompt. Claude 3 Opus learns from the prompt context, so demonstrating the desired input-output behavior can guide it. For instance, if you want it to output data in a particular JSON schema, show a short example of that format in the prompt. Or if you are doing a Q&A over a document and you want answers in a certain style, you might include a sample Q and a well-formatted A as part of the prompt (marked as example). Few-shot prompting often leads to more consistent output structure and can reduce errors in format. However, note that examples count towards the token limit – with a 200K window this is usually fine, but avoid unnecessarily long examples. Make sure your examples are correct (the model might pick up any mistakes in them). After one or two examples, ask it to “follow the same format for the next item”. This technique is powerful for things like list generation, classification tasks, or any scenario where the pattern of the response is crucial.
Encourage Step-by-Step Reasoning for Complex Tasks:
Claude 3 Opus is capable of complex reasoning, but sometimes you need to explicitly invoke it. For multi-step problems (e.g., math word problems, logical reasoning, or code debugging), you can prompt Claude with something like “Let’s think this through step by step.” This is known to trigger a chain-of-thought style answer where the model works out the solution methodically. Anthropic has an “extended thinking” mode in some Claude models that allows deliberation, but even without a special mode, simply instructing the model to show its reasoning can improve outcomes. Another approach is to break the task into sub-questions. For instance, first ask Claude to outline a plan, then feed that plan back in and ask it to execute step 1, and so on (i.e., chain-of-thought across multiple turns). Claude 3 Opus can handle this iterative approach well, especially given the long context to remember prior steps. Example: “Outline the steps to solve this programming problem before giving the final code.” The model might list steps, then you can say “Great, now implement step 1.” This level of control ensures it doesn’t skip critical reasoning. As a developer, you can automate this by programmatically injecting such prompts or by using loops where the model’s previous answer is evaluated and used as context for the next prompt (“self-refinement” loops). The main point is: don’t hesitate to ask Claude to explain or reason – it won’t always do so by default if not requested, but it has the capability internally.
Manage Long Contexts with Deliberation:
When you provide a very large context (say dozens of pages of text), it can help to guide the model on how to use that context. For example, you might start your prompt with: “I am going to give you a 100-page document. Please read it fully. Then, answer the questions that follow. Focus on the parts relevant to the question.” This kind of meta-instruction can improve accuracy. Also, consider using headings or delimiters in the prompt to separate different content sections. Claude doesn’t strictly need it, but a structured prompt (with sections titled “Background”, “Data”, “User Query” etc.) can reduce confusion. Always put images before the related text or at least grouped together; Anthropic notes that Claude performs best on image+text prompts when the image is provided before the textual description or question about it. And as mentioned earlier, put crucial details early. If you have a specific question about the input, ask the question after the entire content (so it’s freshest in context) but maybe also restate key terms of the question at the top as a summary. For example, “Query: Who is the main beneficiary in the will? (Full text of will below…)”. This way, the model knows from the get-go what it’s looking for while reading the will.
Iterate and Refine Prompts:
Treat prompt development as an iterative process. Try your prompt on a variety of cases (Anthropic’s console or Playground is handy for this) and see if Claude’s output meets your needs. If not, adjust the wording or add clarifications. Claude 3 Opus is quite good at taking follow-up instructions in a multi-turn conversation – you can correct it if it misunderstood something. For instance, “Actually, ignore the section about X and focus only on Y,” in a second user message, and it will adjust the next answer. When building a system, you can mimic this by catching unsatisfactory answers and programmatically refining the prompt (or adding a system note like “The assistant should correct any misunderstandings about X”). Over time, you’ll find a prompt approach that reliably yields good results. It’s often helpful to maintain a prompt library or templates for different tasks (e.g., a template for summarization vs. a template for coding help) and reuse them.
Control Output Length and Format:
Use the max_tokens parameter to limit how long the output can be, especially if you want concise answers. If you need a brief answer, you can also say in the prompt “Answer in 3-4 sentences” or “Keep the answer under 100 words.” Claude will usually obey, though if it’s overflowing, the max_tokens will hard-stop it. For structured formats (JSON, XML, code), explicitly instruct the model to output only that format and nothing else. You might wrap the instruction like: “Output only valid JSON with the following fields: …”. Claude is pretty good at following format instructions (partly due to its training on being an assistant that can follow user formatting requests). If you ever get responses that include unwanted text (like apologies or extra commentary), double-check your prompt – it might be because the model is unsure of the task or because the instructions were ambiguous.
Use Stop Sequences and Temperature for Control:
When using the API, stop sequences are a way to tell Claude where to stop generating. For example, Anthropic’s own examples often use a stop sequence like "\n\nHuman:" to stop when the model starts to imagine the user speaking again. This isn’t usually needed in single-turn calls (the model will stop on its own when it finishes the answer), but in multi-turn, it can prevent it from rambling. Also, manage the randomness of output via temperature and top-p settings. A lower temperature (0 to 0.2) keeps the model deterministic and focused (good for factual Q&A or coding where you want the same correct answer every time). A higher temperature (0.7–1.0) injects creativity and variability, which can be useful for brainstorming or creative writing. If you find Claude’s answers too generic, try raising temperature; if it’s too inconsistent or verbose, try lowering it. The top_p parameter can also constrain the output to likelier tokens (setting top_p=0.9, for instance, ensures it only samples from the top 90% probability mass). By tuning these, you have a degree of behavior control over Claude’s style – factual vs. imaginative, terse vs. verbose, etc. In critical applications (like code generation), it’s common to use temperature 0 to ensure reproducibility.
Stay Within Ethical and Policy Bounds:
As a developer, you should be aware that Claude 3 Opus will refuse requests that violate its built-in safety principles (e.g., requests for violence, hate, illicit behavior). It’s much less prone to false refusals now, as mentioned, so you rarely need to “fight” the model to get valid answers. However, if you do hit a refusal for something you believe is a legitimate use, you may need to rephrase the query or clarify your intent to the model. For example, if it refuses a medical question thinking it’s giving advice, you might clarify “This is for a research purpose” or ask it in a hypothetical way. Always avoid trying to jailbreak or break the rules – aside from ethical reasons, it can cause the model to go off-track. Instead, work with the model’s guardrails: e.g., ask for objective information or analysis rather than direct forbidden instructions. Anthropic provides a policy that the model follows; you can actually find summaries of it in their documentation. Ensuring your prompts stay within those guidelines will yield the best results. You can also use the system message to reinforce any project-specific constraints, like “If the user asks for medical advice, provide information and a disclaimer rather than direct advice.”
By following these best practices, developers can significantly improve Claude 3 Opus’s performance and reliability in their applications.
Prompt engineering is often the key differentiator between a mediocre AI integration and a great one. Claude is a sophisticated model, and with the right guidance, it can perform astonishingly well on a wide array of tasks.
Ideal Use Cases for Developers
Claude 3 Opus is a generalist by design, but certain use cases particularly play to its strengths. Here are some ideal scenarios where developers can leverage Claude 3 Opus to get superior results:
Analyzing and Summarizing Long Documents:
One of the most straightforward uses is feeding Claude lengthy documents or knowledge bases and asking for analysis.
For example, a law firm could use Opus to analyze a 100-page legal contract and highlight key obligations of each party, or a medical researcher could have it summarize a stack of research papers.
Claude 3 Opus can comfortably handle documents hundreds of pages long, extracting the “needle from the haystack” with very high recall accuracy. It’s ideally suited for applications like research assistants, report summarizers, or literature review tools.
Enterprises with large text databases (PDFs, manuals, etc.) can integrate Opus to enable semantic search or Q&A over their content.
The model’s vision capability also means if those documents contain charts or images (say, a financial report with graphs), it can interpret those as well, providing a comprehensive analysis in text form.
In short, any use case involving document understanding, summarization, or extraction of insights from long text is a perfect fit for Claude 3 Opus.
Software Development Support and Codebase Q&A:
Claude 3 Opus shines as a coding assistant, especially for large or complex codebases. Developers can use it for on-demand code generation (like “write a function to do X in Python”), code explanation (“explain what this block of code does”), and debugging assistance (“why might this code be throwing an error?”).
Because of the 200K context, you could literally paste tens of thousands of lines of code (from multiple files) and ask Claude to find a bug or suggest improvements across the entire set – something not feasible with smaller context models.
This makes Opus ideal for code review tools, documentation generators, or developer Q&A bots. For instance, a plugin in an IDE could allow a programmer to query Claude about the project’s code (“Where is the user authentication logic implemented?”) and get an answer with references to specific files or functions.
Its understanding of code and algorithms is state-of-the-art, and it performs well on tasks like refactoring code for better efficiency or converting code from one language to another. Startups and companies are already using Claude models to power AI pair programmers in their platforms.
Claude 3 Opus, being the most capable, would be chosen for the hardest programming tasks or for supporting languages that require more knowledge.
An ideal use case here is an AI code consultant for an enterprise: developers can chat with Claude 3 Opus to get help on their internal code (with the model privy to the entire codebase in its context window) – making expertise accessible on demand.
Intelligent Chatbots and Assistants with Memory:
If you’re building a conversational AI that needs to handle lengthy, context-rich dialogues, Claude 3 Opus is a top choice. It can remember what was said dozens of turns ago (even if the conversation spans hours and huge transcripts) and use that information to keep the conversation coherent.
This is critical for customer support bots, tutoring systems, or personal assistants that should recall user preferences or past questions.
For example, a customer support AI using Claude could handle an extended troubleshooting session, referencing details the user provided earlier without asking them to repeat.
Or a virtual tutor could track a student’s progress through a curriculum and adapt its teaching, remembering which concepts gave the student trouble.
Claude 3 Opus’s ability to maintain context and perform reasoning means such an assistant can also manage multi-step tasks: for instance, an AI agent that plans a travel itinerary – it can take the user’s preferences, search various options (perhaps via tools), and come up with a plan, all within one conversation.
Anthropic specifically notes Opus is great for agentic tasks where the AI needs to plan and execute complex actions or navigate open-ended instructions.
If your chatbot needs to integrate tool usage (e.g., call APIs, retrieve information), Claude 3 Opus can be guided via prompting to output structured actions (Anthropic has demonstrated this with “Agents” in later Claude versions).
Use cases like virtual assistants, scheduling bots, or multi-turn booking systems can benefit from Opus’s reliability and memory.
Data Analysis and Technical Reasoning:
Claude 3 Opus is capable of parsing and analyzing not only natural language but also structured data and technical information. A great use case is plugging Claude into a data analytics workflow – for instance, providing it CSV or JSON data (within a prompt) and asking analytical questions.
While it’s not a spreadsheet formula solver per se, it can observe patterns or compute derived insights if the data size is reasonable. It can also describe graphs or trends if given raw data or an image of a chart.
This is useful for business intelligence tools where an executive might ask in plain English, “What were the sales trends for region X vs region Y in Q3?” – behind the scenes, the system can supply the sales data to Claude and get back an analysis in narrative form.
Financial services could use it for things like earnings report analysis, where Claude reads a 30-page earnings report and summarizes the financial health of the company.
Its strong reasoning also helps in forecasting and strategy: given enough background, it can discuss scenarios or make reasoned predictions (always caveated as a model).
Anthropic’s partnership announcements mention using Opus for tasks like complex financial forecasting and market trend analysis.
Essentially, high-end analytics that require reading a lot of information and applying expert reasoning (something like a management consultant or data analyst might do) is a sweet spot for Claude 3 Opus.
Knowledge Management and Research Tools:
Organizations with massive knowledge bases (wikis, documentation, intranet pages) can deploy Claude 3 Opus to power search and Q&A systems.
Instead of keyword search, users can ask natural questions and Claude will scan the provided knowledge (supplied in the prompt, possibly retrieved by an external search) to answer. Because of the long context, you can feed in multiple relevant documents at once and get a consolidated answer.
This is ideal for an internal AI knowledge assistant that employees can query for company-specific information. Similarly, in scientific or academic research, Opus can help researchers by summarizing findings across numerous papers, suggesting hypotheses, or even critiquing a draft.
The model’s ability to realize when it’s being tested (like noticing an implausible inserted sentence in the NIAH test) suggests it’s quite savvy – this kind of AI could assist in fact-checking or detecting anomalies in text content as well.
Think of use cases like: a legal research assistant (provide laws and prior cases, ask questions), a medical literature review bot (provide many study abstracts, ask for comparative analysis), or an educational tutor that has the textbook in context and can answer any question from it.
Multilingual and Translation Applications:
Because Claude 3 Opus handles multiple languages at a high level, developers can use it for translation or cross-lingual tasks. For instance, you could build a translation assistant that not only translates text but also explains nuances or checks for tone consistency.
Or a chatbot that can seamlessly switch languages based on the user’s input. Another use case is content generation in languages other than English – e.g., generating a summary of an English document in French, or writing a marketing email in Spanish from English bullet points.
Claude’s language understanding is broad, so it can also be used for tasks like sentiment analysis or intent recognition in different languages, which many monolingual models struggle with.
Essentially, any application that needs AI capabilities across languages (global customer support, international content creation, localization of documents) could leverage Claude 3 Opus to ensure high-quality results in each language.
Creative and Generative Applications:
While one might primarily think of Claude Opus for analysis, it’s also very capable in creative domains. Developers working on apps for story generation, game mastering, or content ideation can use Opus to generate rich, coherent creative text.
For example, a storytelling app could use Claude to generate dynamic narratives based on user choices (with the long context tracking the story so far). A game might use it to power intelligent NPC dialogue that stays consistent over a long interaction.
In marketing, it can generate personalized ad copy or social media content at scale, adjusting style per the prompt. It’s even feasible to use Claude to draft design documents or strategy memos given bullet points.
The main advantage in creative tasks is the coherence and context length – Opus can keep track of many details (characters in a story, or requirements in a product spec) and weave them together in the output.
Its creative writing competence is high, so tasks that require a bit of flair along with knowledge (like writing a fictitious scenario that still needs to be plausible, or an educational story that incorporates facts) are a great fit.
These examples only scratch the surface. The key is: Claude 3 Opus is best used when the problem is complex, the input is large or detailed, and the solution requires intelligence and context awareness.
If you have a use case where simpler models fall short – maybe they can’t handle the length or they make too many reasoning mistakes – that’s where Claude 3 Opus is worth the investment.
Developers across industries (from finance to healthcare to education) are finding that tasks such as long-form document analysis, expert content generation, high-level reasoning, and complex coding tasks are significantly enhanced by Claude 3 Opus.
By understanding the model’s strengths and integrating it thoughtfully, you can build applications that were previously impractical or impossible with weaker AI. Claude 3 Opus truly opens up new frontiers for AI-powered development, enabling solutions that operate on a higher level of context and intelligence than ever before.